作者按:本文根据去年11月份CSDN举办的“大数据技术大会”演讲材料整理,最初发表于2012年2月期《程序员》杂志。
1. 历史
R(R Development Core Team, 2011)语言由新西兰奥克兰大学的 Ross Ihaka 和 Robert Gentleman 两人共同发明,其词法和语法分别源自 Scheme 和 S 语言,R 语言一般认为是 S 语言(John Chambers, Bell Labs, 1972)的一种方言。R 是“GNU S”, 一个自由的、有效的、用于统计计算和绘图的语言和环境,它提供了广泛的统计分析和绘图技术:包括线性和非线性模型、统计检验、时间序列、分类、聚类等方法。我们更倾向于认为 R 是一个环境,在 R 环境里实现了很多经典的、现代的统计技术。

1992 年,Ross Ihaka 和Robert Gentleman 在奥克兰大学成为同事。后来为了方便教授初等统计课程,二人开发了一种语言;而他们名字的首字母都是R,于是R 便成为了这门语言的名称。
作为 R 语言的前身——S 语言的代码几乎不需要进行任何修改即可在R 语言环境下运行,从这个角度讲两种语言几乎等价。S 语言诞生于上个世纪 70 年代的由 John M. Chambers 领导的贝尔实验室统计部,它的诞生过程几乎就是现代统计分析方式的演化历程的写照1:
- 1975-1976 年,贝尔实验室统计研究部使用一套文档齐全的 Fortran 库做统计研究,简称为 SCS ( Statistical Computing Subroutines );
- 当时的商业统计软件采用的是批处理的方式,一次性输出问题的所有相关的信息,在那个时代,这个过程需要几个小时,并且商业软件不能对程序做任何修改。而贝尔实验室的统计学家们需要灵活的交互式数据分析方式,因此 SCS 在贝尔实验室非常受欢迎;
- 但统计学家们发现使用 SCS 做统计分析时需要大量的 Fortran 编程,花在编程上的时间同取得的分析效果相比有些得不偿失。慢慢地,大家达成了一个共识:统计分析不应该需要编写 Fortran 程序!
- 于是,为了同 SCS 进行交互,一套完整的高级语言系统 S 诞生了;
- S 语言的理念,用它的发明者John Chambers 的话说就是“to turn ideas into software, quickly and faithfully.”
1993 年,S语言的许可证被 MathSoft 公司买断,S-PLUS 成为了其公司的主打数据分析产品,这时候,由于 S-PLUS继承了S语言的优秀血统,所以广泛被世界各国的统计学家所使用。但好景不长,1997年R语言正式成为了 GNU 项目,大量的优秀统计学家加入到了R语言开发的行列。随着R语言的功能愈发强大,渐渐地S-PLUS的用户转到了同承一脉的R语言。S语言的发明人之一,John M. Chambers 最终也成为了R语言的核心团队成员。S-PLUS这款优秀的软件也几经易手,最后花落TIBCO公司,这是后话。
John Chambers老爷子一直不遗余力的致力于R语言的发展,至今仍然是活跃的R语言开发者。在2009年第一期R Journal上John Chambers是这样对R语言是定义的:
- An interface to computational procedures of many kinds;
- Interactive, hands-on in real time;
- Functional in its model of programming;
- Object-oriented, “everything is an object”;
- Modular, built from standardized pieces; and,
- Collaborative, a world-wide, open-source effort.
当然,R 语言的这些特点很难在一篇短文里细致的体现出来,那下面我将简要的描述一下 R 语言的现状和未来。
2. 现状及应用
R语言在国际和国内的发展差异非常大,国际上R语言已然是专业数据分析领域的标准,但在国内依旧任重而道远,这固然有数据学科地位的原因,国人版权概念薄弱以及学术领域相对闭塞也是原因。那为什么R语言能够被广大的数据分析工作者做接受?这其中原因是很多的:
2.1 优势及特点
从R语言的发展历史上看,R主要是统计学家为解决数据分析领域问题而开发的语言,因此R具有一些独特的优势:
- 统计学家和几乎覆盖整个统计领域的前沿算法(3700+ 扩展包)
- 开放的源代码(free, in both senses),可以部署在任何操作系统,比如 Windows, Linux, Mac OS X, BSD, Unix强大的社区支持
- 高质量、广泛的统计分析、数据挖掘平台
- 重复性的分析工作(Sweave = R + LATEX),借助 R 语言的强大的分析能力 + LaTeX 完美的排版能力,可以自动生成分析报告
- 方便的扩展性
- 可通过相应接口连接数据库,如 Oracle、DB2、MySQL
- 同 Python、Java、C、C++ 等语言进行互调
- 提供 API 接口均可以调用,比如 Google、Twitter、Weibo
- 其他统计软件大部分均可调用 R,比如 SAS、SPSS、Statistica等
- 甚至一些比较直接的商业应用,比如 Oracle R Enterprise, IBM Netezza, R add-on for Teradata, SAP HANA, Sybase RAP2
2.2 荣誉
R 语言拥有这么多优势,很大部分原因是由于它同样继承了 S 语言的优秀血统。S 语言在1998 年被美国计算机协会(ACM)授予了软件系统奖,这是迄今为止众多统计软件中“唯一”被 ACM 授予的统计系统。
当时 ACM 是这样评价S 语言的:
- 永久的改变了人们分析、可视化、处理数据的方式;
- 是一个优雅的,被广泛接受的,不朽的软件系统。
我们也可以查询到历年 ACM 授予软件系统奖的列表,这些优秀的软件系统同我们的生活息息相关:
- 1983 Unix
- 1986 TeX
- 1989 PostScript
- 1991 TCP/IP
- 1995 World-Wide-Web
- 1997 Tcl/Tk
- 1998 S
- 1999 The Apache Group
- 2002 Java
2009 年纽约时报发表了题为 “Data Analysts Captivated by R’s Power”的社评,集中的讨论了R语言在数据分析领域的发展,并引发了SAS和R用户广泛而激烈的争论。接下来的2010年,美国统计协会(American Statistical Association)又将第一届“统计计算及图形奖” 授予了R语言,用于表彰其在统计应用和统计研究广泛的影响。
2.3 社团及活动
正如前文John Chambers所说,R也是一个社区,其线下的活动也是非常活跃。在国际上,欧洲和美国每年会轮值举办一次useR! 会议,届时来自于世界各地的R用户齐聚一堂,讨论R语言的应用与科研方面的成果。出于对统计计算的特殊考虑,每两年还会举办一次DSC会议(Directions in Statistical Computing),专门讨论R在统计计算方面的应用及理论研究。各大城市也会有相应的R Group,方便本地的R用户聚会及交流。
在国内,每年会以统计之都牵头在北京和上海举办两次中国R语言会议,至今年已经在中国人民大学、华东师范大学等高校举办了四届R语言会议,历年的演讲主题涉及医药、金融、地理信息、统计图形、数据挖掘、制药、高性能计算、社会学、生物信息学、互联网等多个领域,从明年起,台北将成为第三个举办中国R语言会议的城市,2012年6月的中华R语言会议台北场已经在筹划当中。
2.4 业界的认可
KDnuggets 网站每年都会做一些数据分析、数据挖掘方面的专题问卷调查,在2011年8月份的数据挖掘领域语言流行度的调查中,R语言位于数据挖掘领域居于所有语言之首(图2),而紧随其后的SQL、Python、Java则是在某一领域具有各自的独到优势。在数据挖掘范畴下,R语言同这些语言相互补足、相得益彰。
根据互联网搜索结果计算的TIOBE 编程社区指数(Programming Community Index)3可能更能代表编程语言的流行度。在2011年12月份排名中,R 语言依旧是在统计领域中最为流行的语言,位列第 24(Ratings 0.522%),而时常被放在一起比较的SAS 则排名第31(0.417%)。
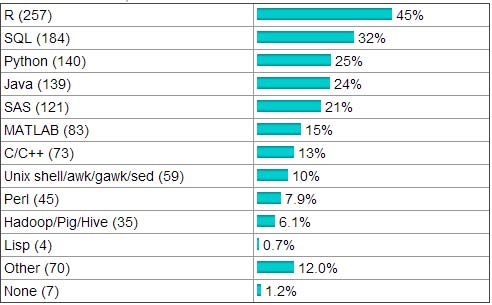
虽然KDnuggets 网站的调查存在样本有偏的嫌疑,但毕竟代表了某一类人群的偏好。并 且排名前五位的语言在各自的领域确有代表性。数据来源http://www.kdnuggets.com/2011/08/poll-languages-for-data-mining-analytics.html
3. 挑战和未来
虽然R语言有诸多的优势,但R语言不是万能的,它毕竟是统计编程类语言。受到其算法架构的通用性以及速度性能方面的影响,因此其初始设计完全基于单线程和纯粹的内存计算。虽然一般情况下无关 R 的使用,在当今大数据条件下,这两个设计思路的劣势逐渐变得愈加刺眼,好在R的一些优秀的扩展性包解决了上述问题,比如:
- snow 支持MPI、PVM、nws、sockets 通讯,解决单线程和内存限制;
- multicore 适合大规模计算环境,主要解决单线程问题;
- parallel R 2.14.0 版本增加的标准包,整合了snow 和multicore 功能;
- R + Hadoop 在Hadoop 集群上运行R 代码,亦或操作Hive 仓库;
- RHIPE 更友好的R 代码运行环境,解决单线程和内存限制;
- Segue 利用Amazon’s Web Services(EC2)。
这里需要着重提一下parallel包,这个包是R核心团队为了解决大数据计算问题而在标准安装程序下新增的功能包。
3.1 一些误区
很多人认为R语言是GNU开源项目软件,因此软件的使用是“没有任何保证” 的。但在美国,R的计算结果被 FDA(Food and Drug Administration)所承认;并且有报告指出R相比其他商业软件,bug数量非常少4!
R开发的核心团队对于R的新功能持异常谨慎的态度,比如cairographics从2007开始酝酿,直到上一个大版本(2011 年)才引入到R标准安装程序;byte-compile功能更是经历了1999-2011 近12年的孵化5。从这个角度讲,R语言的代码质量以及运算结果的可信性是完全可以保证的。
当然,这里所说的是R的标准安装程序包,并不代表所有的扩展包的质量。毕竟3700+的扩展包良莠不齐,虽然不乏一些优秀的包(如Rcpp, RODBC, VGAM, rattle),但必然存在一些扩展包质量不佳的情况。
3.2 应用的思考
R 语言并不是人人都会接触到的语言,相对要小众很多,有些人即便接触到没准也搞不清楚R到底是做什么用途。对于走上这条路的人,经常会有一些应用困难,比如对个人学习角度而言:
- 虽然R语言的设计之初就是避免通过大量编程实现统计算法,但最基本的编程能力还是需要的,因此对于一般非计算机专业的工作者来说无疑提高了难度;
- 还有很多人提到,R语言的学习曲线非常陡峭。但从个人这么多年的使用经验上看,陡峭的学习曲线并不是R语言本身的,而是隐藏在后面的统计知识很难在短时间内掌握的缘故。
从公司商业应用的角度而言,也存在一些不可回避的问题:
- 首先是人力资源成本如何核算;
- 软件成本问题,由于R是自由软件,可以随时随地下载,因此对于企业来说如何度量成本是一个问题;
- R 的技能核定并没有官方或机构标准,简历上“熟练使用R 语言” 可能没有任何意义;
- 实际上,即便没有上述两个问题,那企业想找到R相关的人才不那么简单;
- 对于大量工作已经由其他软件实现(比如用SAS)的公司来讲,转化成本很高;
- 技术支持获取的问题。
4. 结语
R语言虽然诞生于统计社区,服务于数据,但现在随着数据渗透到各行各业,R语言已经远远超过统计范畴,相信不久的将来会有更多的朋友加入到R语言社区。
- 谢益辉,郑冰(2008). R 语言的历史背景、发展历程和现状. 1st China R Conference. ↩
- 刘思喆(2012). 商业数据库对 r 语言的支持.http://www.bjt.name/2012/04/r-language-enterprise/. ↩
- TIOBE (2011). http://www.tiobe.com/index.php/content/paperinfo/tpci/index.html. ↩
- UCLA (2006). R relative to statistical packages. Technical report, UCLA. ↩
- Ripley, B. (2011). The r development process. Technical report, Department of Statistics, University of Oxford. ↩
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表/查看评论