Author:张丹(Conan)
Date: 2013-04-07
Weibo: @Conan_Z
Email: bsspirit@gmail.com
Blog: http://www.fens.me/blog
APPs:
@晒粉丝 http://www.fens.me
@每日中国天气 http://apps.weibo.com/chinaweatherapp
RHadoop实践系列文章
RHadoop实践系列文章,包含了R语言与Hadoop结合进行海量数据分析。Hadoop主要用来存储海量数据,R语言完成MapReduce 算法,用来替代Java的MapReduce实现。有了RHadoop可以让广大的R语言爱好者,有更强大的工具处理大数据。1G, 10G, 100G, TB,PB 由于大数据所带来的单机性能问题,可能会一去联复返了。
RHadoop实践是一套系列文章,主要包括“Hadoop环境搭建”,“RHadoop安装与使用”,“R实现MapReduce的算法案 例”,“HBase和rhbase的安装与使用”。对于单独的R语言爱好者,Java爱好者,或者Hadoop爱好者来说,同时具备三种语言知识并不容 易。
由于rmr2的对hadoop操作有一些特殊性,代码实现有一定难度。需要深入学习的同学,请多尝试并思考key/value值的设计。
本文难度为中高级。
第三篇 R实现MapReduce的协同过滤算法,分为3个章节。
1.基于物品推荐的协同过滤算法介绍
2.R本地程序实现
3.R基于Hadoop分步式程序实现
每一章节,都会分为“文字说明部分”和“代码部分”,保持文字说明与代码的连贯性。
注:Hadoop环境及RHadoop的环境,请查看同系列前二篇文章,此文将不再介绍。
1. 基于物品推荐的协同过滤算法介绍
文字说明部分:
越来越多的互联网应用,都开始使用推荐算法(协同过滤算法)。根据用户活跃度和物品流行度,可以分为“基于用户的协同过滤算法”和“基于物品的协同过滤算法”。
基于用户的协同过滤算法,是给用户推荐和他兴趣相似的其他用户喜欢的物品。
基于物品的协同过滤算法,是给用户推荐和他之前喜欢的物品相似的物品。
基于物品的协同过滤算法,是目前广泛使用的一种推荐算法,像Netflix, YouTube, Amazon等。
算法主要分为两步:
计算物品之间的相似度
根据物品的相似度和用户的历史行为给用户生成推荐列表
有关算法的细节请参考:“Mahout In Action”和“推荐系统实践”两本书。
为开发方便,我们选择一组很小的测试数据集。
测试数据,来自于“Mahout In Action” P49
原第8行,3,101,2.5 改为 3,101,2.0
每行3个字段,依次是用户ID,物品ID,对物品的评分
代码部分:
在服务上创建测试数据文件small.csv
~ pwd
/root/R
~ vi small.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.0
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0
~ ls
small.csv
2. R本地程序实现
首先,通过R语言实现基于物品的协同过滤算法,为和RHadoop实现进行对比。这里我使用“Mahout In Action”书里,第一章第六节介绍的分步式基于物品的协同过滤算法进行实现。Chapter 6: Distributing recommendation computations
算法的思想:
建立物品的同现矩阵
建立用户对物品的评分矩阵
矩阵计算推荐结果
文字说明部分:
- 建立物品的同现矩阵
按用户分组,找到每个用户所选的物品,单独出现计数,及两两一组计数。
例如:用户ID为3的用户,分别给101,104,105,107,这4个物品打分。
1) (101,101),(104,104),(105,105),(107,107),单独出现计算各加1。
2) (101,104),(101,105),(101,107),(104,105),(104,107),(105,107),两个一组计数各加1。
3) 把所有用户的计算结果求和,生成一个三角矩阵,再补全三角矩阵,就建立了物品的同现矩阵。
如下面矩阵所示:
[101] [102] [103] [104] [105] [106] [107]
[101] 5 3 4 4 2 2 1
[102] 3 3 3 2 1 1 0
[103] 4 3 4 3 1 2 0
[104] 4 2 3 4 2 2 1
[105] 2 1 1 2 2 1 1
[106] 2 1 2 2 1 2 0
[107] 1 0 0 1 1 0 1
- 建立用户对物品的评分矩阵
按用户分组,找到每个用户所选的物品及评分
例如:用户ID为3的用户,分别给(3,101,2.0),(3,104,4.0),(3,105,4.5),(3,107,5.0),这4个物品打分。
1) 找到物品评分(3,101,2.0),(3,104,4.0),(3,105,4.5),(3,107,5.0)
2) 建立用户对物品的评分矩阵
U3
[101] 2.0
[102] 0.0
[103] 0.0
[104] 4.0
[105] 4.5
[106] 0.0
[107] 5.0
- 矩阵计算推荐结果
同现矩阵*评分矩阵=推荐结果
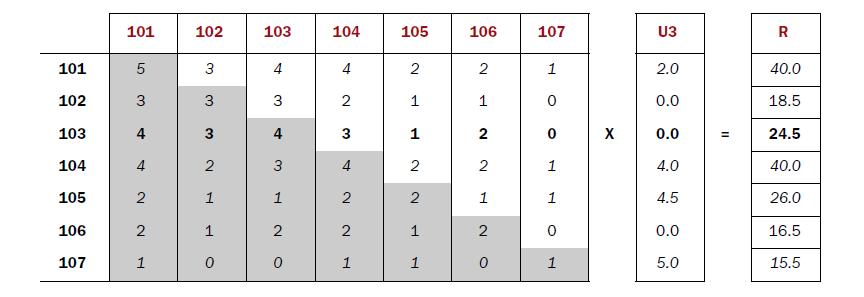
图片摘自“Mahout In Action”
推荐给用户ID为3的用户的结果是(103,24.5),(102,18.5),(106,16.5)
代码部分:
#引用plyr包
library(plyr)
#读取数据集
train<-read.csv(file="small.csv",header=FALSE)
names(train)<-c("user","item","pref")
> train
user item pref
1 1 101 5.0
2 1 102 3.0
3 1 103 2.5
4 2 101 2.0
5 2 102 2.5
6 2 103 5.0
7 2 104 2.0
8 3 101 2.0
9 3 104 4.0
10 3 105 4.5
11 3 107 5.0
12 4 101 5.0
13 4 103 3.0
14 4 104 4.5
15 4 106 4.0
16 5 101 4.0
17 5 102 3.0
18 5 103 2.0
19 5 104 4.0
20 5 105 3.5
21 5 106 4.0
#计算用户列表
usersUnique<-function(){
users<-unique(train$user)
users[order(users)]
}
#计算商品列表方法
itemsUnique<-function(){
items<-unique(train$item)
items[order(items)]
}
# 用户列表
users<-usersUnique()
> users
[1] 1 2 3 4 5
# 商品列表
items<-itemsUnique()
> items
[1] 101 102 103 104 105 106 107
#建立商品列表索引
index<-function(x) which(items %in% x)
data<-ddply(train,.(user,item,pref),summarize,idx=index(item))
> data
user item pref idx
1 1 101 5.0 1
2 1 102 3.0 2
3 1 103 2.5 3
4 2 101 2.0 1
5 2 102 2.5 2
6 2 103 5.0 3
7 2 104 2.0 4
8 3 101 2.0 1
9 3 104 4.0 4
10 3 105 4.5 5
11 3 107 5.0 7
12 4 101 5.0 1
13 4 103 3.0 3
14 4 104 4.5 4
15 4 106 4.0 6
16 5 101 4.0 1
17 5 102 3.0 2
18 5 103 2.0 3
19 5 104 4.0 4
20 5 105 3.5 5
21 5 106 4.0 6
#同现矩阵
cooccurrence<-function(data){
n<-length(items)
co<-matrix(rep(0,n*n),nrow=n)
for(u in users){
idx<-index(data$item[which(data$user==u)])
m<-merge(idx,idx)
for(i in 1:nrow(m)){
co[m$x[i],m$y[i]]=co[m$x[i],m$y[i]]+1
}
}
return(co)
}
#推荐算法
recommend<-function(udata=udata,co=coMatrix,num=0){
n<-length(items)
# all of pref
pref<-rep(0,n)
pref[udata$idx]<-udata$pref
# 用户评分矩阵
userx<-matrix(pref,nrow=n)
# 同现矩阵*评分矩阵
r<-co %*% userx
# 推荐结果排序
r[udata$idx]<-0
idx<-order(r,decreasing=TRUE)
topn<-data.frame(user=rep(udata$user[1],length(idx)),item=items[idx],val=r[idx])
topn0),]
# 推荐结果取前num个
if(num>0){
topn<-head(topn,num)
}
#返回结果
return(topn)
}
#生成同现矩阵
co<-cooccurrence(data)
> co
[,1] [,2] [,3] [,4] [,5] [,6] [,7]
[1,] 5 3 4 4 2 2 1
[2,] 3 3 3 2 1 1 0
[3,] 4 3 4 3 1 2 0
[4,] 4 2 3 4 2 2 1
[5,] 2 1 1 2 2 1 1
[6,] 2 1 2 2 1 2 0
[7,] 1 0 0 1 1 0 1
#计算推荐结果
recommendation<-data.frame()
for(i in 1:length(users)){
udata<-data[which(data$user==users[i]),]
recommendation<-rbind(recommendation,recommend(udata,co,0))
}
> recommendation
user item val
1 1 104 33.5
2 1 106 18.0
3 1 105 15.5
4 1 107 5.0
5 2 106 20.5
6 2 105 15.5
7 2 107 4.0
8 3 103 24.5
9 3 102 18.5
10 3 106 16.5
11 4 102 37.0
12 4 105 26.0
13 4 107 9.5
14 5 107 11.5
3. R基于Hadoop分步式程序实现
R语言实现的MapReduce算法,可以基于R的数据对象实现,不必如JAVA一样使用文本存储。
算法思想同上面R语言实现思想,略有复杂。
算法的思想:
- 建立物品的同现矩阵
1) 按用户分组,得到所有物品出现的组合列表。
2) 对物品组合列表进行计数,建立物品的同现矩阵
建立用户对物品的评分矩阵
合并同现矩阵和评分矩阵
计算推荐结果列表
按输入格式得到推荐评分列表
通过MapReduce实现时,所有操作都要使用Map和Reduce的任务完成,程序实现过程略有变化。
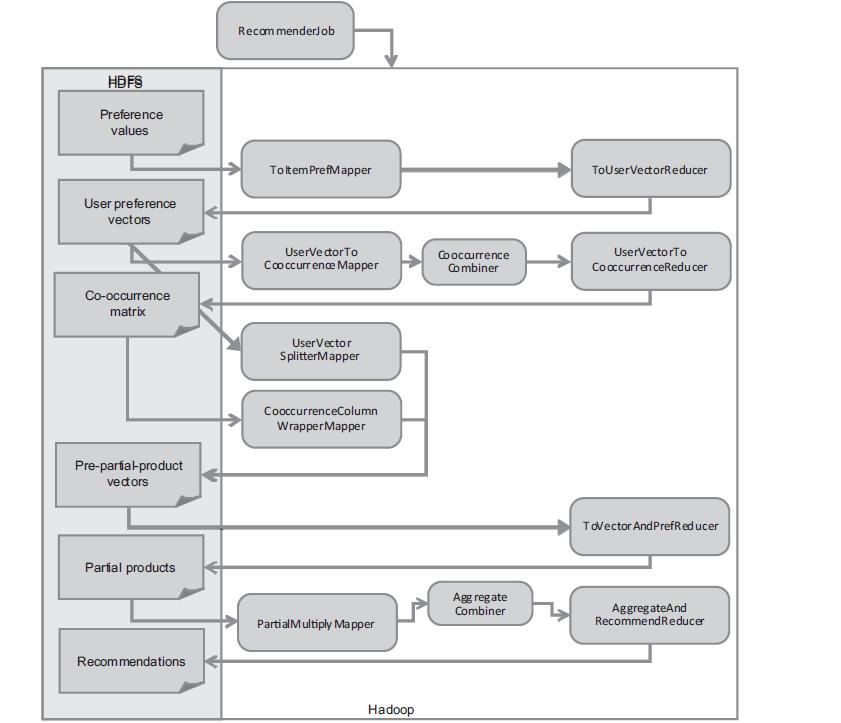
图片摘自“Mahout In Action”
文字说明部分:
- 建立物品的同现矩阵
1) 按用户分组,得到所有物品出现的组合列表。
key:物品列表向量
val:物品组合向量
$key
[1] 101 101 101 101 101 101 101 101 101 101 101 101 101 101 101 102 102 102 102
[20] 102 102 102 103 103 103 103 103 103 103 103 103 103 103 104 104 104 104 104
[39] 104 104 104 104 104 104 104 105 105 105 105 106 106 106 106 107 107 107 107
[58] 101 101 101 101 101 101 102 102 102 102 102 102 103 103 103 103 103 103 104
[77] 104 104 104 104 104 105 105 105 105 105 105 106 106 106 106 106 106
$val
[1] 101 102 103 101 102 103 104 101 104 105 107 101 103 104 106 101 102 103 101
[20] 102 103 104 101 102 103 101 102 103 104 101 103 104 106 101 102 103 104 101
[39] 104 105 107 101 103 104 106 101 104 105 107 101 103 104 106 101 104 105 107
[58] 101 102 103 104 105 106 101 102 103 104 105 106 101 102 103 104 105 106 101
[77] 102 103 104 105 106 101 102 103 104 105 106 101 102 103 104 105 106
2) 对物品组合列表进行计数,建立物品的同现矩阵
key:物品列表向量
val:同现矩阵的数据框值(item,item,Freq)
矩阵格式,要与“2. 建立用户对物品的评分矩阵”的格式一致,把异构的两种数据源,合并为同一种数据格式,为“3. 合并 同现矩阵 和 评分矩阵”做数据基础。
$key
[1] 101 101 101 101 101 101 101 102 102 102 102 102 102 103 103 103 103 103 103
[20] 104 104 104 104 104 104 104 105 105 105 105 105 105 105 106 106 106 106 106
[39] 106 107 107 107 107
$val
k v freq
1 101 101 5
2 101 102 3
3 101 103 4
4 101 104 4
5 101 105 2
6 101 106 2
7 101 107 1
8 102 101 3
9 102 102 3
10 102 103 3
11 102 104 2
12 102 105 1
13 102 106 1
14 103 101 4
15 103 102 3
16 103 103 4
17 103 104 3
18 103 105 1
19 103 106 2
20 104 101 4
21 104 102 2
22 104 103 3
23 104 104 4
24 104 105 2
25 104 106 2
26 104 107 1
27 105 101 2
28 105 102 1
29 105 103 1
30 105 104 2
31 105 105 2
32 105 106 1
33 105 107 1
34 106 101 2
35 106 102 1
36 106 103 2
37 106 104 2
38 106 105 1
39 106 106 2
40 107 101 1
41 107 104 1
42 107 105 1
43 107 107 1
- 建立用户对物品的评分矩阵
key:物品列表
val:用户对物品打分矩阵
矩阵格式,要与”2) 对物品组合列表进行计数,建立物品的同现矩阵”的格式一致,把异构的两种数据源,合并为同一种数据格式,为”3. 合并 同现矩阵 和 评分矩阵”做数据基础
$key
[1] 101 101 101 101 101 102 102 102 103 103 103 103 104 104 104 104 105 105 106
[20] 106 107
$val
item user pref
1 101 1 5.0
2 101 2 2.0
3 101 3 2.0
4 101 4 5.0
5 101 5 4.0
6 102 1 3.0
7 102 2 2.5
8 102 5 3.0
9 103 1 2.5
10 103 2 5.0
11 103 4 3.0
12 103 5 2.0
13 104 2 2.0
14 104 3 4.0
15 104 4 4.5
16 104 5 4.0
17 105 3 4.5
18 105 5 3.5
19 106 4 4.0
20 106 5 4.0
21 107 3 5.0
- 合并 同现矩阵 和 评分矩阵
这一步操作是MapReduce比较特殊的,因为数据源是两个异构数据源,进行MapReduce的操作。
在之前,我们已经把两种格式合并为一样的。使用equijoin这个rmr2包的函数,进行矩阵合并。
key:NULL
val:合并的数据框
$key
NULL
$val
k.l v.l freq.l item.r user.r pref.r
1 103 101 4 103 1 2.5
2 103 102 3 103 1 2.5
3 103 103 4 103 1 2.5
4 103 104 3 103 1 2.5
5 103 105 1 103 1 2.5
6 103 106 2 103 1 2.5
7 103 101 4 103 2 5.0
8 103 102 3 103 2 5.0
9 103 103 4 103 2 5.0
10 103 104 3 103 2 5.0
11 103 105 1 103 2 5.0
12 103 106 2 103 2 5.0
13 103 101 4 103 4 3.0
....
- 计算推荐结果列表
把第三步中的矩阵,进行合并计算,得到推荐结果列表
key:物品列表
val:推荐结果数据框
$key
[1] 101 101 101 101 101 101 101 101 101 101 101 101 101 101 101 101 101 101
[19] 101 101 101 101 101 101 101 101 101 101 101 101 101 101 101 101 101 102
[37] 102 102 102 102 102 102 102 102 102 102 102 102 102 102 102 102 102 103
[55] 103 103 103 103 103 103 103 103 103 103 103 103 103 103 103 103 103 103
[73] 103 103 103 103 103 104 104 104 104 104 104 104 104 104 104 104 104 104
[91] 104 104 104 104 104 104 104 104 104 104 104 104 104 104 104 105 105 105
[109] 105 105 105 105 105 105 105 105 105 105 105 106 106 106 106 106 106 106
[127] 106 106 106 106 106 107 107 107 107
$val
k.l v.l user.r v
1 101 101 1 25.0
2 101 101 2 10.0
3 101 101 3 10.0
4 101 101 4 25.0
5 101 101 5 20.0
6 101 102 1 15.0
7 101 102 2 6.0
8 101 102 3 6.0
9 101 102 4 15.0
10 101 102 5 12.0
11 101 103 1 20.0
12 101 103 2 8.0
13 101 103 3 8.0
14 101 103 4 20.0
15 101 103 5 16.0
16 101 104 1 20.0
17 101 104 2 8.0
18 101 104 3 8.0
....
- 按输入格式得到推荐评分列表
对推荐结果列表,进行排序处理,输出排序后的推荐结果。
key:用户ID
val:推荐结果数据框
$key
[1] 1 1 1 1 1 1 1 2 2 2 2 2 2 2 3 3 3 3 3 3 3 4 4 4 4 4 4 4 5 5 5 5 5 5 5
$val
user item pref
1 1 101 44.0
2 1 103 39.0
3 1 104 33.5
4 1 102 31.5
5 1 106 18.0
6 1 105 15.5
7 1 107 5.0
8 2 101 45.5
9 2 103 41.5
10 2 104 36.0
11 2 102 32.5
12 2 106 20.5
13 2 105 15.5
14 2 107 4.0
15 3 101 40.0
16 3 104 38.0
17 3 105 26.0
18 3 103 24.5
19 3 102 18.5
20 3 106 16.5
21 3 107 15.5
22 4 101 63.0
23 4 104 55.0
24 4 103 53.5
25 4 102 37.0
26 4 106 33.0
27 4 105 26.0
28 4 107 9.5
29 5 101 68.0
30 5 104 59.0
31 5 103 56.5
32 5 102 42.5
33 5 106 34.5
34 5 105 32.0
35 5 107 11.5
rmr2使用提示:
1) rmr.options(backend = ‘hadoop’)
这里backend有两个值,hadoop,local。hadoop是默认值,使用hadoop环境运行程序。local是一个本地测试的设置,已经不建议再使用。我在开发时,试过local设置,运行速度非常快,模拟了hadoop的运行环境。但是,local模式下的代码,不能和hadoop模式下完全兼容,变动也比较大,因此不建议大家使用。
2) equijoin(…,outer=c(‘left’))
这里outer包括了4个值,c(“”, “left”, “right”, “full”),非常像数据库中两个表的join操作
3) keyval(k,v)
mapReduce的操作,需要key和valve保存数据。如果直接输出,或者输出的未加key,会有一个警告Converting to.dfs argument to keyval with a NULL key。再上一篇文章中,rmr2的例子中就有类似的情况,请大家注意修改代码。
> to.dfs(1:10)
Warning message:
In to.dfs(1:10) : Converting to.dfs argument to keyval with a NULL key
代码部分:
#加载rmr2包
library(rmr2)
#输入数据文件
train<-read.csv(file="small.csv",header=FALSE)
names(train)<-c("user","item","pref")
#使用rmr的hadoop格式,hadoop是默认设置。
rmr.options(backend = 'hadoop')
#把数据集存入HDFS
train.hdfs = to.dfs(keyval(train$user,train))
from.dfs(train.hdfs)
> from.dfs(train.hdfs)
13/04/07 14:35:44 INFO util.NativeCodeLoader: Loaded the native-hadoop library
13/04/07 14:35:44 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
13/04/07 14:35:44 INFO compress.CodecPool: Got brand-new decompressor
$key
[1] 1 1 1 2 2 2 2 3 3 3 3 4 4 4 4 5 5 5 5 5 5
$val
user item pref
1 1 101 5.0
2 1 102 3.0
3 1 103 2.5
4 2 101 2.0
5 2 102 2.5
6 2 103 5.0
7 2 104 2.0
8 3 101 2.0
9 3 104 4.0
10 3 105 4.5
11 3 107 5.0
12 4 101 5.0
13 4 103 3.0
14 4 104 4.5
15 4 106 4.0
16 5 101 4.0
17 5 102 3.0
18 5 103 2.0
19 5 104 4.0
20 5 105 3.5
21 5 106 4.0
#STEP 1, 建立物品的同现矩阵
# 1) 按用户分组,得到所有物品出现的组合列表。
train.mr<-mapreduce(
train.hdfs,
map = function(k, v) {
keyval(k,v$item)
}
,reduce=function(k,v){
m<-merge(v,v)
keyval(m$x,m$y)
}
)
from.dfs(train.mr)
$key
[1] 101 101 101 101 101 101 101 101 101 101 101 101 101 101 101 102 102 102 102
[20] 102 102 102 103 103 103 103 103 103 103 103 103 103 103 104 104 104 104 104
[39] 104 104 104 104 104 104 104 105 105 105 105 106 106 106 106 107 107 107 107
[58] 101 101 101 101 101 101 102 102 102 102 102 102 103 103 103 103 103 103 104
[77] 104 104 104 104 104 105 105 105 105 105 105 106 106 106 106 106 106
$val
[1] 101 102 103 101 102 103 104 101 104 105 107 101 103 104 106 101 102 103 101
[20] 102 103 104 101 102 103 101 102 103 104 101 103 104 106 101 102 103 104 101
[39] 104 105 107 101 103 104 106 101 104 105 107 101 103 104 106 101 104 105 107
[58] 101 102 103 104 105 106 101 102 103 104 105 106 101 102 103 104 105 106 101
[77] 102 103 104 105 106 101 102 103 104 105 106 101 102 103 104 105 106
# 2) 对物品组合列表进行计数,建立物品的同现矩阵
step2.mr<-mapreduce(
train.mr,
map = function(k, v) {
d<-data.frame(k,v)
d2<-ddply(d,.(k,v),count)
key<-d2$k
val<-d2
keyval(key,val)
}
)
from.dfs(step2.mr)
$key
[1] 101 101 101 101 101 101 101 102 102 102 102 102 102 103 103 103 103 103 103
[20] 104 104 104 104 104 104 104 105 105 105 105 105 105 105 106 106 106 106 106
[39] 106 107 107 107 107
$val
k v freq
1 101 101 5
2 101 102 3
3 101 103 4
4 101 104 4
5 101 105 2
6 101 106 2
7 101 107 1
8 102 101 3
9 102 102 3
10 102 103 3
11 102 104 2
12 102 105 1
13 102 106 1
14 103 101 4
15 103 102 3
16 103 103 4
17 103 104 3
18 103 105 1
19 103 106 2
20 104 101 4
21 104 102 2
22 104 103 3
23 104 104 4
24 104 105 2
25 104 106 2
26 104 107 1
27 105 101 2
28 105 102 1
29 105 103 1
30 105 104 2
31 105 105 2
32 105 106 1
33 105 107 1
34 106 101 2
35 106 102 1
36 106 103 2
37 106 104 2
38 106 105 1
39 106 106 2
40 107 101 1
41 107 104 1
42 107 105 1
43 107 107 1
# 2. 建立用户对物品的评分矩阵
train2.mr<-mapreduce(
train.hdfs,
map = function(k, v) {
#df<-v[which(v$user==3),]
df<-v
key<-df$item
val<-data.frame(item=df$item,user=df$user,pref=df$pref)
keyval(key,val)
}
)
from.dfs(train2.mr)
$key
[1] 101 101 101 101 101 102 102 102 103 103 103 103 104 104 104 104 105 105 106
[20] 106 107
$val
item user pref
1 101 1 5.0
2 101 2 2.0
3 101 3 2.0
4 101 4 5.0
5 101 5 4.0
6 102 1 3.0
7 102 2 2.5
8 102 5 3.0
9 103 1 2.5
10 103 2 5.0
11 103 4 3.0
12 103 5 2.0
13 104 2 2.0
14 104 3 4.0
15 104 4 4.5
16 104 5 4.0
17 105 3 4.5
18 105 5 3.5
19 106 4 4.0
20 106 5 4.0
21 107 3 5.0
#3. 合并同现矩阵 和 评分矩阵
eq.hdfs<-equijoin(
left.input=step2.mr,
right.input=train2.mr,
map.left=function(k,v){
keyval(k,v)
},
map.right=function(k,v){
keyval(k,v)
},
outer = c("left")
)
from.dfs(eq.hdfs)
$key
NULL
$val
k.l v.l freq.l item.r user.r pref.r
1 103 101 4 103 1 2.5
2 103 102 3 103 1 2.5
3 103 103 4 103 1 2.5
4 103 104 3 103 1 2.5
5 103 105 1 103 1 2.5
6 103 106 2 103 1 2.5
7 103 101 4 103 2 5.0
8 103 102 3 103 2 5.0
9 103 103 4 103 2 5.0
10 103 104 3 103 2 5.0
11 103 105 1 103 2 5.0
12 103 106 2 103 2 5.0
13 103 101 4 103 4 3.0
14 103 102 3 103 4 3.0
15 103 103 4 103 4 3.0
16 103 104 3 103 4 3.0
17 103 105 1 103 4 3.0
18 103 106 2 103 4 3.0
19 103 101 4 103 5 2.0
20 103 102 3 103 5 2.0
21 103 103 4 103 5 2.0
22 103 104 3 103 5 2.0
23 103 105 1 103 5 2.0
24 103 106 2 103 5 2.0
25 101 101 5 101 1 5.0
26 101 102 3 101 1 5.0
27 101 103 4 101 1 5.0
28 101 104 4 101 1 5.0
29 101 105 2 101 1 5.0
30 101 106 2 101 1 5.0
31 101 107 1 101 1 5.0
32 101 101 5 101 2 2.0
33 101 102 3 101 2 2.0
34 101 103 4 101 2 2.0
35 101 104 4 101 2 2.0
36 101 105 2 101 2 2.0
37 101 106 2 101 2 2.0
38 101 107 1 101 2 2.0
39 101 101 5 101 3 2.0
40 101 102 3 101 3 2.0
41 101 103 4 101 3 2.0
42 101 104 4 101 3 2.0
43 101 105 2 101 3 2.0
44 101 106 2 101 3 2.0
45 101 107 1 101 3 2.0
46 101 101 5 101 4 5.0
47 101 102 3 101 4 5.0
48 101 103 4 101 4 5.0
49 101 104 4 101 4 5.0
50 101 105 2 101 4 5.0
51 101 106 2 101 4 5.0
52 101 107 1 101 4 5.0
53 101 101 5 101 5 4.0
54 101 102 3 101 5 4.0
55 101 103 4 101 5 4.0
56 101 104 4 101 5 4.0
57 101 105 2 101 5 4.0
58 101 106 2 101 5 4.0
59 101 107 1 101 5 4.0
60 105 101 2 105 3 4.5
61 105 102 1 105 3 4.5
62 105 103 1 105 3 4.5
63 105 104 2 105 3 4.5
64 105 105 2 105 3 4.5
65 105 106 1 105 3 4.5
66 105 107 1 105 3 4.5
67 105 101 2 105 5 3.5
68 105 102 1 105 5 3.5
69 105 103 1 105 5 3.5
70 105 104 2 105 5 3.5
71 105 105 2 105 5 3.5
72 105 106 1 105 5 3.5
73 105 107 1 105 5 3.5
74 106 101 2 106 4 4.0
75 106 102 1 106 4 4.0
76 106 103 2 106 4 4.0
77 106 104 2 106 4 4.0
78 106 105 1 106 4 4.0
79 106 106 2 106 4 4.0
80 106 101 2 106 5 4.0
81 106 102 1 106 5 4.0
82 106 103 2 106 5 4.0
83 106 104 2 106 5 4.0
84 106 105 1 106 5 4.0
85 106 106 2 106 5 4.0
86 104 101 4 104 2 2.0
87 104 102 2 104 2 2.0
88 104 103 3 104 2 2.0
89 104 104 4 104 2 2.0
90 104 105 2 104 2 2.0
91 104 106 2 104 2 2.0
92 104 107 1 104 2 2.0
93 104 101 4 104 3 4.0
94 104 102 2 104 3 4.0
95 104 103 3 104 3 4.0
96 104 104 4 104 3 4.0
97 104 105 2 104 3 4.0
98 104 106 2 104 3 4.0
99 104 107 1 104 3 4.0
100 104 101 4 104 4 4.5
101 104 102 2 104 4 4.5
102 104 103 3 104 4 4.5
103 104 104 4 104 4 4.5
104 104 105 2 104 4 4.5
105 104 106 2 104 4 4.5
106 104 107 1 104 4 4.5
107 104 101 4 104 5 4.0
108 104 102 2 104 5 4.0
109 104 103 3 104 5 4.0
110 104 104 4 104 5 4.0
111 104 105 2 104 5 4.0
112 104 106 2 104 5 4.0
113 104 107 1 104 5 4.0
114 102 101 3 102 1 3.0
115 102 102 3 102 1 3.0
116 102 103 3 102 1 3.0
117 102 104 2 102 1 3.0
118 102 105 1 102 1 3.0
119 102 106 1 102 1 3.0
120 102 101 3 102 2 2.5
121 102 102 3 102 2 2.5
122 102 103 3 102 2 2.5
123 102 104 2 102 2 2.5
124 102 105 1 102 2 2.5
125 102 106 1 102 2 2.5
126 102 101 3 102 5 3.0
127 102 102 3 102 5 3.0
128 102 103 3 102 5 3.0
129 102 104 2 102 5 3.0
130 102 105 1 102 5 3.0
131 102 106 1 102 5 3.0
132 107 101 1 107 3 5.0
133 107 104 1 107 3 5.0
134 107 105 1 107 3 5.0
135 107 107 1 107 3 5.0
#4. 计算推荐结果列表
cal.mr<-mapreduce(
input=eq.hdfs,
map=function(k,v){
val<-v
na<-is.na(v$user.r)
if(length(which(na))>0) val<-v[-which(is.na(v$user.r)),]
keyval(val$k.l,val)
}
,reduce=function(k,v){
val<-ddply(v,.(k.l,v.l,user.r),summarize,v=freq.l*pref.r)
keyval(val$k.l,val)
}
)
from.dfs(cal.mr)
$key
[1] 101 101 101 101 101 101 101 101 101 101 101 101 101 101 101 101 101 101
[19] 101 101 101 101 101 101 101 101 101 101 101 101 101 101 101 101 101 102
[37] 102 102 102 102 102 102 102 102 102 102 102 102 102 102 102 102 102 103
[55] 103 103 103 103 103 103 103 103 103 103 103 103 103 103 103 103 103 103
[73] 103 103 103 103 103 104 104 104 104 104 104 104 104 104 104 104 104 104
[91] 104 104 104 104 104 104 104 104 104 104 104 104 104 104 104 105 105 105
[109] 105 105 105 105 105 105 105 105 105 105 105 106 106 106 106 106 106 106
[127] 106 106 106 106 106 107 107 107 107
$val
k.l v.l user.r v
1 101 101 1 25.0
2 101 101 2 10.0
3 101 101 3 10.0
4 101 101 4 25.0
5 101 101 5 20.0
6 101 102 1 15.0
7 101 102 2 6.0
8 101 102 3 6.0
9 101 102 4 15.0
10 101 102 5 12.0
11 101 103 1 20.0
12 101 103 2 8.0
13 101 103 3 8.0
14 101 103 4 20.0
15 101 103 5 16.0
16 101 104 1 20.0
17 101 104 2 8.0
18 101 104 3 8.0
19 101 104 4 20.0
20 101 104 5 16.0
21 101 105 1 10.0
22 101 105 2 4.0
23 101 105 3 4.0
24 101 105 4 10.0
25 101 105 5 8.0
26 101 106 1 10.0
27 101 106 2 4.0
28 101 106 3 4.0
29 101 106 4 10.0
30 101 106 5 8.0
31 101 107 1 5.0
32 101 107 2 2.0
33 101 107 3 2.0
34 101 107 4 5.0
35 101 107 5 4.0
36 102 101 1 9.0
37 102 101 2 7.5
38 102 101 5 9.0
39 102 102 1 9.0
40 102 102 2 7.5
41 102 102 5 9.0
42 102 103 1 9.0
43 102 103 2 7.5
44 102 103 5 9.0
45 102 104 1 6.0
46 102 104 2 5.0
47 102 104 5 6.0
48 102 105 1 3.0
49 102 105 2 2.5
50 102 105 5 3.0
51 102 106 1 3.0
52 102 106 2 2.5
53 102 106 5 3.0
54 103 101 1 10.0
55 103 101 2 20.0
56 103 101 4 12.0
57 103 101 5 8.0
58 103 102 1 7.5
59 103 102 2 15.0
60 103 102 4 9.0
61 103 102 5 6.0
62 103 103 1 10.0
63 103 103 2 20.0
64 103 103 4 12.0
65 103 103 5 8.0
66 103 104 1 7.5
67 103 104 2 15.0
68 103 104 4 9.0
69 103 104 5 6.0
70 103 105 1 2.5
71 103 105 2 5.0
72 103 105 4 3.0
73 103 105 5 2.0
74 103 106 1 5.0
75 103 106 2 10.0
76 103 106 4 6.0
77 103 106 5 4.0
78 104 101 2 8.0
79 104 101 3 16.0
80 104 101 4 18.0
81 104 101 5 16.0
82 104 102 2 4.0
83 104 102 3 8.0
84 104 102 4 9.0
85 104 102 5 8.0
86 104 103 2 6.0
87 104 103 3 12.0
88 104 103 4 13.5
89 104 103 5 12.0
90 104 104 2 8.0
91 104 104 3 16.0
92 104 104 4 18.0
93 104 104 5 16.0
94 104 105 2 4.0
95 104 105 3 8.0
96 104 105 4 9.0
97 104 105 5 8.0
98 104 106 2 4.0
99 104 106 3 8.0
100 104 106 4 9.0
101 104 106 5 8.0
102 104 107 2 2.0
103 104 107 3 4.0
104 104 107 4 4.5
105 104 107 5 4.0
106 105 101 3 9.0
107 105 101 5 7.0
108 105 102 3 4.5
109 105 102 5 3.5
110 105 103 3 4.5
111 105 103 5 3.5
112 105 104 3 9.0
113 105 104 5 7.0
114 105 105 3 9.0
115 105 105 5 7.0
116 105 106 3 4.5
117 105 106 5 3.5
118 105 107 3 4.5
119 105 107 5 3.5
120 106 101 4 8.0
121 106 101 5 8.0
122 106 102 4 4.0
123 106 102 5 4.0
124 106 103 4 8.0
125 106 103 5 8.0
126 106 104 4 8.0
127 106 104 5 8.0
128 106 105 4 4.0
129 106 105 5 4.0
130 106 106 4 8.0
131 106 106 5 8.0
132 107 101 3 5.0
133 107 104 3 5.0
134 107 105 3 5.0
135 107 107 3 5.0
#5. 按输入格式得到推荐评分列表
result.mr<-mapreduce(
input=cal.mr,
map=function(k,v){
keyval(v$user.r,v)
}
,reduce=function(k,v){
val<-ddply(v,.(user.r,v.l),summarize,v=sum(v))
val2<-val[order(val$v,decreasing=TRUE),]
names(val2)<-c("user","item","pref")
keyval(val2$user,val2)
}
)
from.dfs(result.mr)
$key
[1] 1 1 1 1 1 1 1 2 2 2 2 2 2 2 3 3 3 3 3 3 3 4 4 4 4 4 4 4 5 5 5 5 5 5 5
$val
user item pref
1 1 101 44.0
2 1 103 39.0
3 1 104 33.5
4 1 102 31.5
5 1 106 18.0
6 1 105 15.5
7 1 107 5.0
8 2 101 45.5
9 2 103 41.5
10 2 104 36.0
11 2 102 32.5
12 2 106 20.5
13 2 105 15.5
14 2 107 4.0
15 3 101 40.0
16 3 104 38.0
17 3 105 26.0
18 3 103 24.5
19 3 102 18.5
20 3 106 16.5
21 3 107 15.5
22 4 101 63.0
23 4 104 55.0
24 4 103 53.5
25 4 102 37.0
26 4 106 33.0
27 4 105 26.0
28 4 107 9.5
29 5 101 68.0
30 5 104 59.0
31 5 103 56.5
32 5 102 42.5
33 5 106 34.5
34 5 105 32.0
35 5 107 11.5
文章中提供了R用MapReduce方法,实现协同过滤算法的一种思路。
算法可能不是最优的,希望大家有时间写出更好的算法来!随着R语言及Hadoop的发展,相信会有越来越多的算法应用会使用这种方式!
如有问题请给我留言,我很高兴与大家讨论。
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表/查看评论