本文转载自施涛的博客,原文链接请点击此处。
大数据时代的悄然到来和计算能力爆炸式增长,让做统计分析的各类人士不禁要重新打量一下自己的技能包,看看是不是很快要被时代浪潮以大浪淘沙的方式清洗掉了。
到底大数据是怎么来的呢?可以用来干什么呢?我们就先拿2012美国总统大选来举个例子看看。比如说我们想预测在2012年11月6日,
- 问题1: 奥巴马和罗姆尼谁当选美国总统?
我们可以用什么数据来做这个预测呢?最常用的就是民调数据了,通过有选择性的挑选一些可能选民来问他们的倾向。这好像是个传统统计干的事。早在1962年John Tukey就已经开始做了。

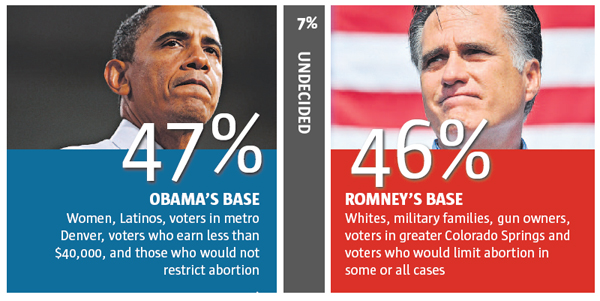
- 问题2: 奥巴马和罗姆尼各自赢得了哪些州?
这也不难回答,我们还是可以用民调数据了,只不过要在每个州都进行抽样调查,在仔细的分析汇总一下。数据量也就比预测全国的结果时用的多几十倍而已。而且如果知道了那些州两人相差太大,一方就没有必要再大肆花钱做广告了 :)
- 问题3: 奥巴马和罗姆尼各自赢得了县?
再做更小范围,更详细的抽样调查也许可行,也就是在加上几十到几百的数据量和相应的花费吧,同时为了提高准确性我们或许还需要收集和用到更多的其他辅助数据,比如各地的人口构成,年龄构成。。。但这个问题如果回答的好的话就可以更有效的投放广告到地方市场了。
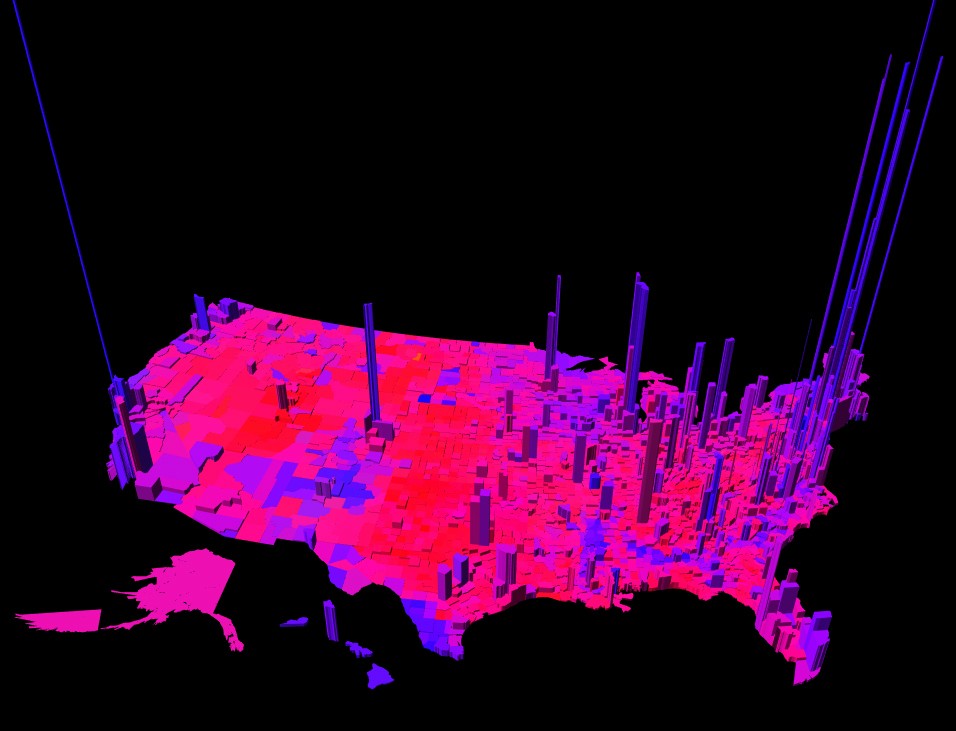
(这个数据可视化很灿,还有更酷的在这里,by Robert J. Vanderbei, Professor of Operations Research and Financial Engineering at Princeton。看,不是统计学家做的吧。)
- 问题4: 奥巴马或罗姆尼赢得某个人的选票的机会?
对这个问题的回答就比较费些劲了,这就牵扯到选战中的精细估计(micro-targeting)了。如果这个估计的可以做的准,对于摇晃选民就可以电话或上门拜访,狂轰滥炸,试图说服了。
那怎么对每个人的投票倾向有个好的估计呢?关于个人很多因素就可以粉墨登场了,比如:党派,年龄,性别,职业,婚姻情况,家庭人数,所开汽车型号,所用手机型号,等等。。。这数据量一下就上去了。再加上这些年随着社交网络的兴起,我们可以在用上个人和其他人的社交关系,朋友活动,发帖转帖等等等。。。一下子数据量级就上去了,也就可以成为大数据了。这些海量数据也让我们有机会回答以前很难想到能够回答的问题。
从这几个关心问题的转变过程中,我们可以看到与问题对应的所需数据收集和分析方法的演化。当我们关心的问题越细节,越多样化,所需要的资源和技术就越多。
问题5: 如果把第4个问题中的“奥巴马或罗姆尼赢得某个人的选票的机会?”改成“某个人在上网时点击某个展示广告的机会”会怎么样呢?
我们这就看到 Google, Baidu等一拥而上,不计成本的计算了,而且所能应用的变量就可能是他们能拿到关于“某人”的所有的线上脚印和线下信息了。
问题问了一圈,这些听起来都很是十足的统计分析啊。本应该是统计分析人士应该是施展才华的时代,那为何还会有要被时代淘汰的论调呢?记得Leo Brieman 在1994年Berkeley 统计系毕业典礼上的讲话中提到的:
要知道何去何从,我们必须清楚自己真正所擅长的是什么。统计的核心是什么?需要我们是一流的数学家吗?几乎不用。那是什么呢?成为收集信息,分析信息,并得出结论的专家!这才是我们真正所擅长的。所以我认为,这正是我们统计学家应有的定位,我们的身份危机才会到解决。
在大数据的时代,我们还有资格说我们是“收集信息,分析信息,并得出结论的专家” 吗?如果我们不具备收集和处理大数据所需要的计算能力和技巧,没有数据分析的直觉和经验,如何能得出有说服力和经得起检验的结论呢?
现在讨论我们是否是一流的数学家好像已经没有很么意义。我们不妨问问自己,比起一流的计算机学家,我们还有何优势能更好的“收集信息,分析信息,并得出结论”?当我们数据收集和处理能力越来越强时,大家关心的问题的范围也越来越广,细节要求越来越高,需要的数据越来越多。这个发展趋势不广在商业,计算机信息领域天天看到,我们在科学研究,医疗制药,政府服务等各个方面的能力和雄心都在爆炸式的增长,由此带来的问题和分析需求也在爆炸。
在这形势下,我们可以考虑一下在这些牵扯大数据的问题中,统计又如何能更有效的帮助别人分析问题,得出结论。我们的曾经的神器,极限定理以及其赖以生存的测度理论,是否还有那么神奇和有用呢?与此同时我们欠缺的是什么工具呢?如果我们做的理论问题的假设与实际问题和数据的统计距离太显著,还有没有必要钻这牛角尖?如果我们不和做实际问题的一起工作,一起了解问题的细节,有怎能帮助他们呢?
从另一个角度看,我想在拥有与计算机专业的同事相差不算远的计算机技能的基础上,统计专科在数据收集方法(试验设计,抽样方法等),模型选择以及模型对outlier和模型假设的敏感度,在数据支持下对可能结论的批判型思维,以及对结论的不确定型描述等方面还是很大优势的。不过这些方面的技能好像还都不是简单的靠读理论统计课本能直接学习到或证明数学定理能解决的,它们都是在解决实际问题和数据分析的过程中通过不断犯错误来提高的。
当然了,“拥有与计算机专业的同事相差不算远的计算机技能的基础上” 是一个很大很大的需要检验的假设,要拥有这样的基础需要从课程选择,课外导向,个人学习规划等方面出发主动的学习。就像 Michael Jordan,在#21世纪的计算大会#上做“大数据的分治和统计推断”的主题演讲中提到的(优酷视频):
If you didn’t understand a lot of the talk, it is a bit technical, maybe you should go take some statistics class if you are a computer scientist. If you are a statistician, I don’t know if any of you are here, you probably should take some computer science classes.
The future is for those people who can take these two fields and integrate them into one brain, not having to bring every project to statisticians, trying to have them talking to computer scientists using some translation software. But one brain can bring these ideas jointly together. How do I think about my statistical risk and the errors I’m going to make when data come into a computer and how do I think about stating that so I don’t have to break when I have more than a few hundred thousand data points.
当统计学培养出来的学生能得心应手的对(大)数据进行分析时,叫不叫数据科学就无所谓了,因为社会的需求会最终决定一个专业的方向和发展。
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表/查看评论