摘要:面向小微商户以及个人消费的小微信贷是当前互联网金融的重要发展方向,并且正在经历爆发式增长。在这个增长过程中,如何在没有实物抵押的情况下,通过互联网大数据分析实现快速准确征信是一个非常重要的问题。为此,不同的数据来源将各显神通地为信用评估提供依据。本文将通过一个真实的案例出发,进行分析和探讨,针对用户历史行为数据建立信用评分模型,并通过该模型改进信用评估的预测效果。
关键词: 小微信贷;互联网征信;信用评分;Logistic回归模型
一、业务介绍
1. 行业介绍
小微信贷,我们定义为金额较小,并且没有抵押担保,完全靠信用的借贷行为。小微信贷可以面向个人(2C),也可以面向小微企业(2B)。对于2C类业务而言,常常是小额短期信用贷款,这是贷款是为解决借款人临时性的消费需要而发放的期限在1年以内、金额在20万元及以下的、毋需提供担保的人民币信用贷款。对于2B类业务而言,由于小微企业的信贷需求特点是 “短、小、频、急”,这种小额、短期、分散的特征更类似于零售贷款,对资金流动性的要求更高。
小微信贷的产生具有其深刻的市场原因。在2B层面,小微企业受到传统金融机构的歧视和排挤,资金供给严重不足最终导致了小微企业的营养不良。就其原因,主要是小微企业没有足够的抵押物。而传统银行贷款,往往需要企业提供足够的抵押品。小微企业处于发展初级阶段,有限的资金都必须用在刀口上,所以只有少量资金可以用来购买土地房产等固定资产。于是造成传统银行在小微业务方面的产品较少。这造成了小微企业的融资需求与银行产品不匹配。另一方面,很多小微企业的财务报表不完全,从而造成信息不对称,银行对它们没有足够了解的基础上,不敢轻易放贷。而事实上,对银行来说,相对于大企业业务,小微信贷业务成本更高,这也导致银行放贷动力不足。而恰恰相反,在互联网平台上,信息不对称在一定程度上得到降低,而资金的供需双方在降低了交易成本的情况下直接对接,有些电商平台也开始为自己平台上的中小企业提供融资信贷服务。
图1 银行的大企业贷款与小微企业贷款
在2C方面,个人信用贷款主要为了购车、房屋装修、旅游等消费使用,但一般不能用于支付购房款。一般来说信用良好、有固定居所以及稳定收入、还贷能力充足的人能够申请信用贷款。传统的信贷审核仍然存在以下缺点:效率低、速度慢、准确性差。由于这些问题存在,使其很难适应互联网信贷的审核模式。另一方面,信用卡对普罗大众来说能够支配的信用额度有限。因此,仅依靠金融领域已有产品并不能满足用户对贷款金额以及时效性的细化需求。网络信贷的出现将更快地撮合这一过程,从而大量地减少了时间成本。
自余额宝推出以来,互联网金融的产品如雨后春笋般出现。移动互联网正在逐渐渗透到传统金融的各个环节,目标是使金融能够以更低的成本、更多样化的方式、更优质的体验覆盖更多的人群。网络信贷平台将小额信用贷款用互联网的方式进行了改造,从而更多的小微企业和个人有了融资渠道,并且这一过程变得更加便捷。

图2 个人信用贷款的用途
2.业务背景介绍
由于小微借贷中的借贷并没有抵押和担保,那么唯一依靠的就是个人或者企业的信用,因此征信过程及其重要。而我们关注的要点就在于如何利用互联网平台的海量信息来帮助我们快速准确的完成这一过程。马云在给阿里巴巴员工的一封内部邮件中说,以控制为出发点的IT时代正在走向激活生产力为目的的DT(data technology)数据时代。随着计算机技术的发展,大数据运算变得越来越现实,基于大数据应用服务的公司不断崭露头角。大数据在营销领域的应用将广告变成了“窄告”精准营销,而在互联网金融大热的背景下,大数据在金融业征信方面的应用也在逐渐兴起。
2015年1月5日,中国人民银行印发《关于做好个人征信业务准备工作的通知》,公布了首批获得个人征信牌照的8家机构名单,这8家机构分别为:腾讯征信有限公司、芝麻信用管理有限公司、深圳前海征信中心股份有限公司、鹏元征信有限公司、中诚信征信有限公司、中智诚征信有限公司、拉卡拉信用管理有限公司、北京华道征信有限公司。而央行的征信中心是一个基础数据库,已获批的个人征信机构将提供一些增值和创新服务。所以在征信的平台上,各路英雄将利用起自家数据各显神通。
如何能够在B2C或者P2P平台上也能够使用海量的互联网数据帮助完成征信的过程,是我们希望能够在互联网不断颠覆传统的今天看到的事。本项研究的目标就是通过收集到的用户历史行为数据建立预测用户信用评分的模型。本文的数据收集来自一家小贷公司,为了数据隐私考虑,本文将隐去一部分数据信息以及分析结果,但是不影响分析结果的客观性。
具体而言,我们称提供数据的公司为熊小贷(为公司匿名),熊小贷公司的业务包括2B业务和2C业务。公司已经通过自己的综合数据分析得到了对于2B和2C业务的统一用户信用得分,称为熊得分。但是熊得分广泛针对于公司所有的产品以及所有用户,使得对于特定产品的信用评分对于用户的违约情况预测精度并不高。熊小贷公司希望通过某款产品用户特有信息的数据支持,建立针对该特定产品的用户信用评分模型,预期目标是,通过数据支持建立起的该产品用户信用评分模型对于用户是否违约的预测精确度要高于通用的熊得分。直观了解公司的2B和2C业务可以从图3得出,公司包括针对不同用户的不同产品。例如熊分期是针对熊得分400以上用户的定制产品。在手机客户端下载APP“熊小贷”点击进入即可开始信用生活。之后再点击“熊分期”即可进入产品页面,后续会要求用户进行注册以及填写个人信息等内容。
图3 熊小贷公司产品概况
本案例中将针对已收集的用户信息,匹配公司数据库中的用户交易行为信息,以及已采用“熊分期”产品贷款的用户的违约情况,建立信用评分模型。这一信用模型将是从业务目标出发,结合业务背景而建立的。模型将预测用户的信用评分作为参考,并直接指导业务层面的是否可以对用户发放贷款。具体的数据采集以及变量清理过程将在第二章着重介绍,模型建立将在第三章进行介绍。
二、数据描述
1. 数据采集
熊小贷公司的某股东具有第三方支付渠道,故可以收集到独特的用户通过银行卡的交易信息,注册用户只要通过第三方支付渠道进行交易,就能够被记录在案,而通过用户的手机号,就可以搜索到用户的历史交易行为数据。这一数据源具有其独特的优势,直接避免了传统征信行业中用户自填数据存在的重大问题:a. 对个人或者企业进行评级刻画时维度较为单一,不能得到综合全面的立体式评级;b. 财务数据造假的可能性较大,例如工资自填,如果用户为了得到贷款审批而夸大了公司水平,小贷公司很难进行确认; c. 缺乏其他数据进行交叉验证,使得评级的可靠性降低。但是熊小贷公司采集到的数据则比传统数据丰富得多。熊小贷公司共采集了前文提及的产品“熊分期”对应近3万个注册用户信息,自注册APP起的总交易笔数近450万行,以及相对应的其他信息,这些交易信息所处的时间区间跨度超过一年。其中违约用户近1万个,非违约用户近2万个。值得注意的是,此样本为为模型建立抽取的抽样数据并不代表真实注册用户中的违约用户与非违约用户比例。
具体而言,熊小贷公司的“熊分期”产品所对应的注册用户数据结构主要包括以下四张表格,分别为交易事实表,用户信息表,商户分类信息表,以及银行卡信息表,它们之间的关系如图4所示。这四张表格分别通过不同的关键字连接,具体如下:a. 用户信息表可以通过用户手机号码和交易事实表对应,一个用户手机号码对应多个交易事实记录;b. 商户分类信息表可以通过商户编号和交易事实表对应,多个交易事实可能产生于一个商户编号;c. 银行卡信息表可以通过银行卡的前几位数字(称为卡标首)和交易事实表中的卡号对应。
四张表格中包含的具体变量信息分别如下:
- 用户信息表:手机号,注册渠道(手机APP注册,或者网站注册),身份证(提供数据已加密),提取数据前最近一次的登录时间,注册时间等。
- 商户分类信息表:创建时间,商户号,商户名称,商户1级分类代码,商户1级分类名称,商户2级分类代码,商户2级分类名称,商户3级分类代码,商户3级分类名称,商户4级分类代码,商户4级分类名称等。
- 银行卡信息表(银行卡卡片类型信息):卡标首(银行卡的前几位数据,决定了属于哪一家银行的哪一种类型的卡片),首长度(例如前6位数字决定了卡片类型,则首长度为6),账户类型,账户类型名称(例如储蓄卡或者信用卡),卡代码,银行代码,银行名称等。
- 交易事实表:流水号(每一笔交易会被制定一个流水号码),交易手机号,交易时间,商户号,账单号,支付金额(支付金额等于账单金额加手续费的总和),账单金额,手续费等。
综上所述,上述四张表格可以通过不同的关键字分别进行匹配连接,从而能够对应到一个用户的多行交易信息在下一小节中,我们将详细阐述数据的变量提取过程。
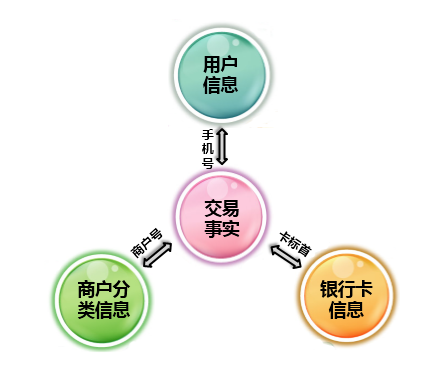
图4 熊分期产品用户数据结构
2.数据清理变量采集
首先,按照关键字将所有四张表格合并。每一条观测以一个用户的一次交易行为为单位,包含用户个人信息,银行卡信息,商户分类信息等,总观测行数近450万条。直接处理并不是一个好的解决方法,这样产生的数据量太大,且不直观利于分析。我们的目标是将所有的信息汇总到每一个用户,定义关于用户的衍生变量。从而,我们分成两个方向的变量来刻画用户特征,分别是:用户基础信息变量以及用户分类信息变量。接下来,我们将进行详细的定义。
用户基础信息变量
此处生成的用户基础信息变量包括直接可以从数据中收集的变量以及衍生变量,如下所示:
(1) 用户的熊得分:由于目标要对于原始的综合熊得分进行预测精度的改进,我们将“熊得分”作为解释变量纳入模型,“熊得分”是熊小贷公司的业务人员根据实际业务定义的指标体系从而生成的得分,我们认为其具备一定的业务经验以及背景知识,从而也具备较强的预测能力。熊得分越低,越有可能违约。
(2,3)用户性别,用户年龄:通过用户身份证号可以提取一个用户的性别,年龄信息,这些数据我们通过与熊小贷公司沟通完成,熊小贷公司并不直接提供用户的身份证号。获取的身份证信息均为加密过后的信息。
(4)用户的注册年龄:即用户从第一次有交易记录开始距离现在的时间长度,以天为单位。
(5)交易笔数:用户自从第一笔交易记录开始,被记录的交易总笔数。
(6)所有行为均值:用户被记录的所有交易行为的平均金额。
(7)所有行为最大值:用户自从第一笔交易开始,所有交易行为的金额的最大值。这个指标可以度量用户的极端行为情况。直观来看,极端行为越大的用户越有可能违约。
(8)借贷比率:用户所有行为中,采用贷记卡(或称为信用卡)交易的次数占所有采用贷记卡或者借记卡(或称为储蓄卡)交易次数的比率。这个指标衡量的是用户的交易习惯,例如,有些人习惯直接采用储蓄卡进行消费,而也有些人习惯每个月采用信用卡先进行消费,到了还款日再按时还款,这样既可以消费,又不影响每个月的理财计划。这两种消费习惯的用户群体不同。
(9)银行卡数:我们每个人需要的银行卡数并不多,银行卡太多的用户与正常用户群体不同。例如,如果需要多张信用卡消费,但是却还不上信用卡的人可能更容易违约。
通过以上信息,我们定义了以上这9个用户基础信息变量。
用户分类信息变量与RFM模型
在征信问题中,我们通常会面临一个典型的问题,在本案例中也是如此,当一个用户对应多条行为关系,如何按照一套既定的指标体系汇总到个人呢?在本案例中,每一个用户对应的交易记录小至几十条,大至一千条,通过交易事实对应到商户分类信息表格,我们可以将其归之为不同类型的交易,例如在超市购物,购买游戏点卡,交水电煤气费用等。对应每一种类别的行为,都需要通过一种标准化的方式计算对应每一个人的变量,来衡量对应一系列行为的人的特征。为此,我们引入营销学中经常采用的RFM模型(参见美国数据库营销研究所Arthur Hughes的研究)。
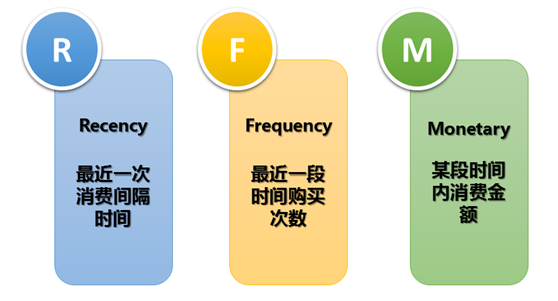
图5 RFM模型图示
在营销领域,RFM模型是用来衡量客户的价值和客户的创利能力的重要工具和手段。这个模型通过一个客户的近期购买行为、购买的总体频率以及花了多少钱三项指标来描述该客户的综合价值,具体如下:
R(Recency),最近一次消费,指上一次购买的时间到现在的距离。理论上,上一次消费时间越近的用户应该是相对而言活跃的用户。因此这些用户对于提供即时的商品或是服务也最有可能产生反应。而我们通常也会发现,对于0到6个月用户收到营销人员的沟通信息会多于31至36个月的用户。
F(Frequency),消费频率,即用户在限定的期间内产生购买的总次数。最常产生购买的用户,忠诚度最高的用户。
M(Monetary),某个用户所有消费金额的平均值。通过这一指标可以验证“帕雷托法则”(Pareto’s Law),也就是说公司80%的收入来自20%的顾客。
在此案例中,我们将重新定义这三个指标,并借助这三个指标来概括用户所产生一类行为的特征,如表格1所示。而由于这三个指标并不能够衡量用户产生行为的波动性,所以我们增加一个指标S(Standard Deviation)来衡量用户行为的波动性。例如,对于购买游戏点卡类行为,我们可以定义R为用户最近一次购买游戏点卡距离数据提取时间的时间间隔,F定义为一年内用户购买游戏点卡的次数(考虑到用户注册时间不一样,此处采用的频数需要采用用户年龄进行标准化,即总次数除以用户年龄。用户年龄的定义将在下文中详述),M定义为一年内用户每次购买游戏点卡的平均金额,S定义为用户每次购买游戏点卡金额的标准差。我们将所有变量记作类别名称加指标简称的形式,例如游戏R。
表1 RFM指标定义
| 指标简称 | 指标定义 |
|---|---|
| R | 一年内用户最后一次产生某类行为距离提取数据的时间 |
| F | 用户在一年内产生某次行为的频数 |
| M | 用户在一年内产生某类行为的平均金额 |
| S | 一年内该类行为产生金额的标准差 |
用户行为的分类通过银行卡信息表,以及商户分类信息表,根据业务场景,我们提取了以下类别,每个类别都对应着以上我们已经定义好的RFMS四个指标。类别包括:
(1)借记类:刻画用户使用储蓄卡的交易行为。不同的用户习惯不同,采用储蓄卡和信用卡的倾向也可能不同。
(2)消费类:刻画用户的日常消费行为。日常消费行为的金额以及频次不同,用户的还款能力可能不同。
(3)信贷类:刻画用户之前的小额贷款类行为。用户之前如果有其他消费贷款类行为可能已经习惯进行消费贷款,从而可能具备更良好的信用状况。
(4)转账类:刻画用户的转账行为。经常通过熊小贷APP转账的用户可能与不转账的用户行为不同。
(5)话费类:刻画用户的话费充值交易行为。话费充值是否规律与充值金额多少都可能意味着用户群体不同。
(6)公缴类:刻画用户交水,电,煤气费等交易行为。公缴费用的多少与是否规律也可能说明用户群体的不同。
(7)游戏类:刻画用户购买游戏点卡的行为。经常玩游戏的用户群体可能与不玩游戏的人不同。
(8,9)四大行卡类以及中型银行卡类:四大行包括中国银行,中国农业银行,中国工商银行,中国建设银行,中型银行包括招商银行,浦发银行,兴业银行,平安银行等。这个指标的设定有以下两方面原因:a. 不同公司的工资卡不同,小型创业公司一般采用中型银行的银行卡;b. 四大行的信用卡发放较为保守,所以能够申请到四大行信用卡的人可能和采用其他银行信用卡的用户群体不同。
(10)白金及金卡类:通过卡标首可以对应到银行卡是属于哪家银行的哪种类型的卡,例如招商银行的金葵花卡。我们搜索整理了相应银行的金卡和白金卡卡种名称,并对应到每一个用户。我们初步认为,拥有白金卡和金卡的用户具备更高的还款能力,所以用户群体不同。
综上所述,我们一共提取了10个类别,每个类别4个指标,共计40个分类信息变量来全方位立体的刻画一个用户的全部交易行为。
数据预处理与数据汇总
为了数据质量考虑,我们去掉“用户注册年龄”小于10天的用户,原因在于,这一部分用户的观察行为较少,并不足以代表稳定的用户自身特征。另外,在对数据进行描述分析后,模型建立之前,我们将所有连续数据做对数处理,并进行标准化。由于所有样本均来自于交易行为的归纳汇总,故只要用户有交易行为,分类信息变量就不存在缺失,故此处不需要缺失数据填补。
最终,我们的数据共包括28816个用户,其中违约用户为9115个,非违约用户19701个;结合9个用户基础信息变量,我们的数据共包括49个解释性变量,这49个变量也包含着对于业务的理解和思考。这对于刻画用户的所有行为而言,只是初步的探索和尝试,但是相较于只采用用户自填信息进行建模而言,已经更为综合和全面。
三、数据建模
在建模部分,我们将先通过几个变量的基础描述分析,以说明变量的特征,继而通过建立逻辑回归模型对于预测效果进行阐述。
1. 描述性分析
出于数据隐私考虑,我们只针对于其中6个变量作箱线图分析。箱线图能提供有关数据位置和分散情况的关键信息,尤其在比较不同的总体数据时更可表现其差异。此处我们通过对比箱线图对数据进行分析。我们用 0表示违约用户, 1表示非违约用户。
(1)熊得分与是否违约。从箱线图可以看出,非违约用户与违约用户的箱线图有明显的差别,这表明熊得分对于违约与非违约用户具有较好的区分度。
(2)交易笔数与是否违约。从箱线图可以看出,非违约用户较违约用户而言,交易笔数更高。
(3)用户所有行为均值与是否违约。从箱线图可以看出,非违约用户与违约用户相比较,所有行为金额的均值较高。
(4)借记卡F与是否违约:通过箱线图可以得出,非违约用户的借记卡F平均高于违约用户。表明非违约用户借记卡的使用频数更高。
(5)四大行M与是否违约:通过箱线图得出,非违约用户的四大行卡的行为平均值较高,这说明非违约用户更多使用四大行的银行卡。
(6)信贷R与是否违约:从图中能够得出结论,非违约用户通过APP产生借贷行为距离现在的日期,相对于违约用户而言较近。
通过以上描述分析,我们已经能够观察到在所提取特征中违约用户与非违约用户的不同,通过回归分析,我们将进一步说明通过变量特征的设定带来的预测效果的提升。
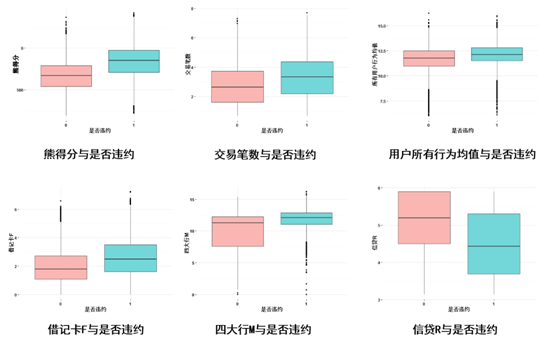
图6 典型变量箱线图
2.模型设定及估计结果
本案例中采用逻辑回归进行建模,原因在于,根据逻辑回归结果,我们能够直观看到每一个变量对于因变量是否违约的作用大小,有利于系数解释。但由于变量过多,我们很难对于所有变量进行符合预期的系数解释,进一步地,我们采用BIC的方法选择模型。相比较于AIC而言,BIC模型选择的方法选择的变量个数较少,更有利于模型的估计系数解释。
BIC选模型的估计系数结果如表2所示,由于系数较多,我们省去估计量的估计误差和P值的具体数值,只用“*”标注P值的大小。但注意,当回归系数过多时我们难以直观展示系数结果,为此,我们根据估计系数的正负将变量分类,再按照绝对值的大小排序整理得到图7和图8。由于模型主要分析“熊得分”之外其他变量带来的预测效果的提升,我们只绘制除“熊得分”之外其他变量的系数。
我们并不逐一解释每一个系数的大小及其含义。值得注意的是,从图7中我们可以总结归纳得出非违约用户的特征,从图8中可以总结归纳出违约用户的特征,通过这两幅图已经可以总结出较为直观的对于违约与非违约用户的理解。我们通过进一步观察可以直观得出的结论包括但不限于:
在其他变量控制不变的情况下,借贷比例越高的用户违约可能性越低,这与银行的信用卡额度提升相似,对于经常使用信用卡并按时还款的客户更有可能被银行认为信用良好,从而希望改用户提高信用额度,而如果不经常使用信用卡则无法判断。从而借贷比例越高,表明用户越习惯使用信用卡,进一步越有可能是信用良好的用户。另一方面,用户申请银行的信用卡需要通过银行的信用评估,故有信用卡的用户较没有信用卡的用户会有所不同。
表2 BIC选模型回归系数结果表
| 变量名 | 估计值 | p值 | 变量名 | 估计值 | p值 |
|---|---|---|---|---|---|
| 熊得分 | 26.301 | *** | 转账R | -0.336 | *** |
| 借贷比率 | 1.752 | *** | 年龄 | -0.254 | *** |
| 借记卡F | 0.438 | *** | 公缴R | -0.230 | |
| 用户所有行为均值 | 0.412 | *** | 四大F | -0.175 | *** |
| 交易笔数 | 0.136 | *** | 四大R | -0.168 | *** |
| 借记卡M | 0.083 | *** | 中型F | -0.122 | *** |
| 中型M | 0.016 | *** | 中型R | -0.119 | ** |
| 四大M | 0.014 | * | 消费F | -0.096 | ** |
| 信贷R | -0.922 | *** | 金卡F | -0.083 | *** |
| 银行卡数 | -0.674 | *** | 转账M | -0.082 | *** |
| 信贷F | -0.633 | *** | 公缴M | -0.062 | ** |
| 用户所有行为最大值 | -0.474 | *** | 游戏M | -0.059 | * |
| 转账F | -0.386 | *** | 信贷S | -0.035 | *** |
| 公缴F | -0.370 | * |
注:***表示P<0.01,**表示0.01≤P<0.05,*表示0.05≤P<0.1。
借记卡F越大用户违约可能性越低。这表明其他变量不变,用户使用储蓄卡频数越高,越可能是信用良好的用户。
在其他变量保持不变的情况下,用户每一次交易行为的平均值越大越可能是非违约用户。
控制其他变量不变,信贷R越小越可能是非违约用户。这一点与之前观察的箱线图吻合,越近产生消费借贷行为的人,越有可能是非违约用户。注意这里产生的借贷行为与Y对应的是否违约并非同一次借贷行为。
其他变量水平不变,银行卡数越多,越有可能是违约用户。
保持其他变量不变,用户行为最大值越大,越可能是违约用户。这也验证了我们之前的结论,用户的极端行为越极端,越有可能是违约用户。
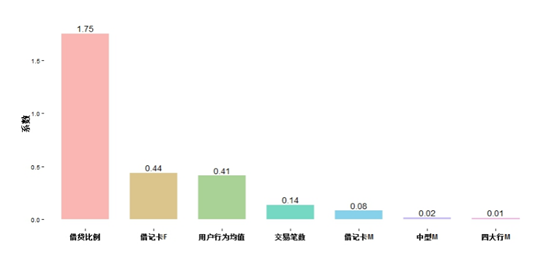
图7 BIC选模型结果正系数
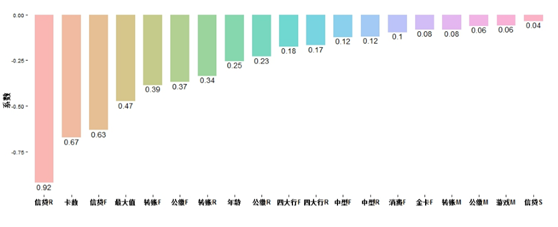
图8 BIC选模型结果负系数
模型预测结果
我们将对比以下三种模型的预测效果,因变量Y相同,为用户是否违约( 1,用户非违约, 0,用户违约):a. 只根据“熊得分”建立的逻辑回归模型;b. 用所有49个变量,包含用户基础信息变量与用户分类信息变量建立的逻辑回归模型;c. 在b模型的基础上通过BIC模型选择方法建立的模型。
衡量模型的预测效果可以采用指标ROC(Receiver Operating Characteristic)曲线或者AUC(Area Under Curve)值。其中ROC曲线的横坐标为false positive rate(FPR),也称为Specificity,刻画的是模型预测错了,认为为1但真实为0的观测占所有真实为0的观测的比例。纵坐标为true positive rate(TPR),也称为Sensitivity,刻画的是模型预测所识别出的为1且真实为1的观测占所有真实为1的观测的比例。ROC曲线越贴近左上角,表明模型的预测效果越好。AUC是ROC曲线下的面积,这一指标取值越大表明模型预测的效果越好。通常在计算中也可以考虑如下公式:
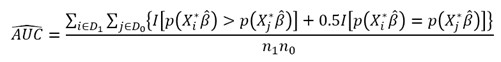
其中 表示 的真实取值为0的集合, 表示 的真实取值为1的集合, 表示 真实取值为0的观测个数, 表示 真实取值为1的观测个数。这一指标可以理解为,真实为1的 的预测非违约可能性不小于真实为0的 的预测非违约可能性的比例。
为了模型对比,我们随机将所有数据划分为训练数据集(80%)和测试数据集(20%), 在训练集上估计模型的回归系数,将所有系数带入测试数据中进行计算,预测非违约可能性。随机拆分被重复了100次。我们随机抽取其中一次绘制ROC曲线如图9所示。其中,Score表示模型a的预测结果,模型中只包含“熊得分”,Full model表示模型b对应的预测结果,BIC表示模型c对应的预测结果。从图中可以得出结论,在b模型与c模型的预测效果接近,二者都要远远好于a模型的预测效果。进一步地,我们将100次随机拆分计算得到的AUC值取平均。出于行业数据机密,我们此处不汇报AUC的绝对提升结果。但是相对于 a模型而言,b模型和c模型的预测效果将相对提升13.6%。这将直接使得我们能够在实际业务中更精准的判断出用户的信用状况。
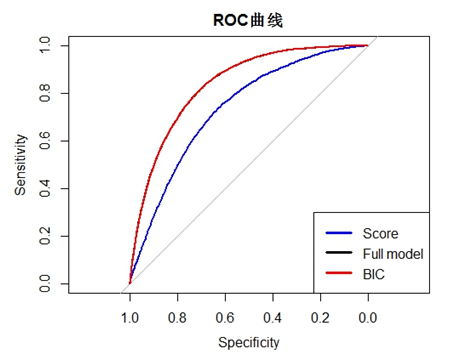
图9 回归模型对比ROC曲线
四、业务实施
对于小贷公司而言,收益是靠收益率体现,而成本则体现在坏账率。也就是说对于现在的市场存在收益和成本的不对等。所以才会有P2P公司如雨后春笋般出现,为了在这个利润丰腴的市场分一杯羹。现在的小贷公司可以通过较为严苛的指标筛选用户,从而保证违约率一直维持在较低的水平,也就是说,现在的网络借贷公司也许并不需要借助纷繁复杂的技术手段就可以获得较高的收益。但是随着市场的饱和,越来越多的公司进入竞争的行列,在可预见的将来,我们可以看到违约率的提高,收益率的下降。到了那时候,拼的不再是跨入市场门槛的勇气,而是谁能够通过技术实力真正的选准用户,稳定住坏账率这一指标。
在业务层面,首先,我们需要通过更多数据来验证以上模型结果真实可靠。通过熊小贷公司提供的不同数据,我们已经验证了这一结果。而通过以上数据建立模型的预测结果可以直接进行以下两方面的工作:
利用预测非违约率来辅助判断是否应该批准用户贷款,即进行用户选择。例如,同样的两个用户申请贷款,A用户的预测非违约率为0.85,B用户的预测非违约率为0.27。那么在资金预算有限的条件下,如果只能批准一个用户进行贷款发放,通过模型就会选择发放给非违约可能性更高的用户A用户。也就是说,通过模型的预测能够帮助我们筛选发放贷款的目标用户。而精准的预测将能够降低我们的贷款成本。
利用预测概率改进APP中的熊得分。例如,通过线性变换可以将预测概率P转化为400至800的用户得分Q,Q=400+400×P。从而能够更新平台上的熊得分,使得熊得分更加准确。
另外,本案例中的模型证实了用户的交易记录数据对于征信模型的重要作用,对于业务上拓展数据源也有重要的指导意义。
五、总结讨论
本文针对互联网征信背景下的信用评估模型进行了探讨,通过具体的案例证明了用户历史行为数据对于用户的信用评估具有重要作用。这其中最值得注意的是,业务背景对于指导建立模型具有不可替代的作用,所有的变量产生都应该建立在对于业务背景知识的透彻了解之上。另外,关于本案例的研究有以下可能的改进方向:
在数据中我们只考虑违约情况为01变量,即,违约与非违约。其中,如果用户违约天数大于等于7天被定义为违约,否则为非违约。如果能够记录用户真实的违约天数作为连续变量,将可能对于模型预测有进一步的帮助。
在本案例中收集的数据只是通过某特定第三方支付平台的所有交易数据,并不能代表用户的所有银行卡交易状况,如果能够收集到用户的所有数据,则将对于用户的交易行为做出更全面客观的刻画。
从本案例的研究中可知,不同平台的数据对于信用评估可能有不同的优势。从央行下发牌照的8家机构看来,不同机构的数据源不同,各具特色,于是如何能够将不同数据源的数据进行统一后,建立综合的信用评估模型,是值得深入探讨的问题。例如,一个用户可能在京东平台和淘宝平台上的信用得分不一样,这与用户的平台偏好有关,但是如果能够根据不同平台的结果综合对用户进行信用评估,则将得到更准确的结果。
参考文献
[1] 陈文. 网络借贷与中小企业融资[M]. 经济管理出版社, 2014.
[2] 胡援成, 卢华征. 中小企业融资的调查与思考[J]. 管理世界, 2003(10):11-13.
[3] 李焰, 高弋君, 李珍妮,等. 借款人描述性信息对投资人决策的影响——基于P2P网络借贷平台的分析[J]. 经济研究, 2014(S1):143-155.
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表/查看评论