如果你是被这个标题骗进来的,那么说明标题党的存在的确是有原因的。 在网络高度发达(以及“大数据”泛滥)的今天,数据动不动就是以 GB 和 TB 的级别存储,然而相比之下,人类接受信息的速度却慢得可怕(参见大刘《乡村教师》)。 试想一下,你一分钟能阅读多少文字?一千?五千?总之是在 KB 的量级。 所以可以说,人们对文字的“下载速度”基本上就是 1~10KB/min。如果拿这个速度去上网的话你还能忍?
既然如此,每天网上有成千上万的新闻、报告、文章和八卦,怎么看得过来呢? 没办法,只能先对正文进行一次粗略的筛选——看标题。俗话说得好,这是一个看脸的世界。 于是乎,文章的作者为了吸引读者,就要取个足够博眼球的标题,而所谓标题党便是充分利用这种心理,用各种颇具创意的标题来吸引读者的注意。
好了,既然看官已经看到了这里,我就可以承认本文其实也是标题党了。 这篇小文并不是要讨论标题党的前世今生,而是研究一个与此有关的统计问题:怎样的标题会更加吸引读者的关注?
这个问题有点太大了,所以我们缩小一下范围。 既然是统计问题,就拿自家的一个例子下手吧:做统计学研究的,都得读各种各样的统计论文,那么论文的标题是否会对这篇文章的阅读量产生影响呢? 巧的是,美国统计协会期刊(JASA)的网站上正好提供了该期刊旗下文章的下载访问量, 所以我们可以以此做一个小分析,来研究一下标题与文章阅读量之间的关系。
可能有读者要问,为什么要使用文章的访问量,而不是引用率呢? 这是因为 JASA 在其网站上说明,访问量数值是指从 JASA 官网下载的统计量,不包括从其他途径(比如购买的论文数据库)的来源。 在 JASA 网站上,下载文章之前读者能获取到的主要是文章的标题和作者信息, 所以访问量的主要驱动因素就是读者在阅读标题和作者之后产生的好奇感,从而减少了数据中的噪音。 相反,引用一篇文章,通常是对文章有了充分理解之后产生的行为,这时候标题的作用可能就非常微弱了。 总而言之,JASA 文章的下载量可以较好地代表读者在获取了文章的基本信息后对它感兴趣的程度。
那么怎么研究文章标题与下载量之间的关系呢? 我们知道,标题是由一个个的单词组成的,如果忽略掉单词之间的语法关系, 我们可以以标题“是否包含某个单词”作为自变量,来看哪些单词与因变量(文章下载量)之间的关系最为显著。 除此之外,我们还需要加上一些其他的自变量,从而更好地解释因变量的变化。本文中我们要考察的变量还包括:
- 作者信息,即文章是否会因为某些大牛是其作者而有非常高的访问量?
- 文章所属的类别,例如是应用类(Applications and Case Studies)的文章更受欢迎还是方法类(Theory and Methods)的阅读量更大?
- 文章所属期数(Issue Number),即更新的文章是否会有更高/低的访问量?
- 文章在页面中的次序,即是否靠前的文章会倾向于有更高的访问量?(联想到竞价排名……)
有了这些数据,我们就可以开始我们的分析了,大体过程如下:
- 截取最近十年的 JASA 文章,获取其标题、作者和下载量等信息;
- 将文章的标题进行分词,构造词频矩阵;
- 类似地,构建文章-作者矩阵;
- 以文章下载量为因变量,对标题、作者和其他自变量作回归;
- 提取重要的变量,考察其系数,以此作为重要性的指标。
下面就对以上过程进行一些更详细的描述。
数据获取
最近十年 JASA 共出刊 41 期(Issue 473 ~ Issue 513),文章大概有 1700 多篇。 我们先获取每一期的的网址,例如 http://www.tandfonline.com/toc/uasa20/101/473, 然后从网页中提取出每篇文章的标题,作者,下载量,文章所属类别,以及每篇文章所在的期数和在该页中的次序。文章最后给出了抓取网页的代码和获取到的数据。
构造词频矩阵
由于是英文期刊,我们基本上可以省掉分词的步骤。对文章标题进行简单的处理,如转换小写,删除停用词之后,就可以构造词频矩阵了。 我们首先构造一个所有文章标题词项的字典,标记为 Term 1 到 Term p,然后词频矩阵的每一行代表一篇文章,每一列代表这个词项在各标题中的词频。
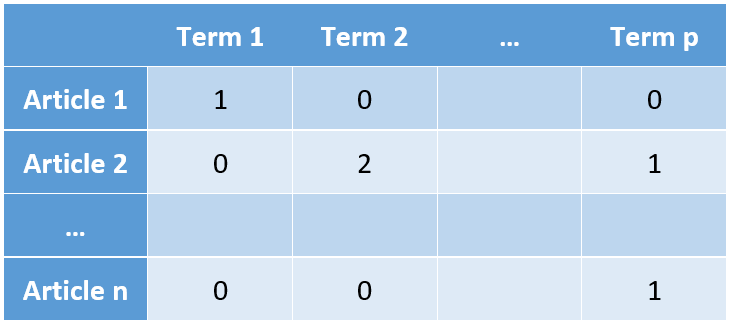
在本文的分析中,我们定义一个词项可以是1~3个连续单词的组合,比如如果文章标题是 Applied linear regression, 那么由此生成的词项就有 applied,linear,regression,applied_linear,linear_regression,applied_linear_regression 共六个。 这么做的原因在于,一个单词的意义有时会依照其上下文而有所变化, 例如同样是 estimation,point estimation 和 interval estimation 就代表了两种风格的文章,所以我们希望考虑到这些变化。
此外,我们希望选出来的词项具有一定的代表性,所以在构造词频矩阵的时候,我们要求每一个词项在文章集合中至少出现过两次。 这样就避免了一些特殊的词语搭配因为出现在某一篇访问量极高的文章中而被挑选出来。
在R中,可以使用text2vec包(https://cran.r-project.org/web/packages/text2vec/index.html)很方便地完成这一过程,代码如下:
library(text2vec)
article_dat = read.csv("jasa.csv", stringsAsFactors = FALSE)
tokens = article_dat$title %>% tolower() %>% word_tokenizer()
sw = c("of", "for", "and", "in", "with", "a",
"the", "to", "on", "an", "by", "its")
it = itoken(tokens)
title_voc = create_vocabulary(it, ngram = c(1, 3), stopwords = sw) %>%
prune_vocabulary(term_count_min = 2)
vectorizer = vocab_vectorizer(title_voc)
it = itoken(tokens)
title_mat = create_dtm(it, vectorizer)
最终该矩阵包括 1753 篇文章和 2552 个词项。
构造文章-作者矩阵
文章-作者矩阵与词频矩阵非常相似,第 i 行第 j 列的元素表示第 j 个人是否是第 i 篇文章的作者,取值为 1 或 0。 同样,为了避免单独一篇文章过大的影响,我们只包括最近十年至少在 JASA 上发过两篇文章的作者。最终该矩阵包括 1753 篇文章和 615 位作者。
Lasso 回归建模
加上类别、期数和页内次序的信息后,我们共有 1753 个观测和 3180 个自变量。 由于变量数大于观测数,我们将采用 Lasso 来对自变量进行筛选。此外,因变量的分布严重右偏,所以我们预先对其进行对数变换后再进行建模。
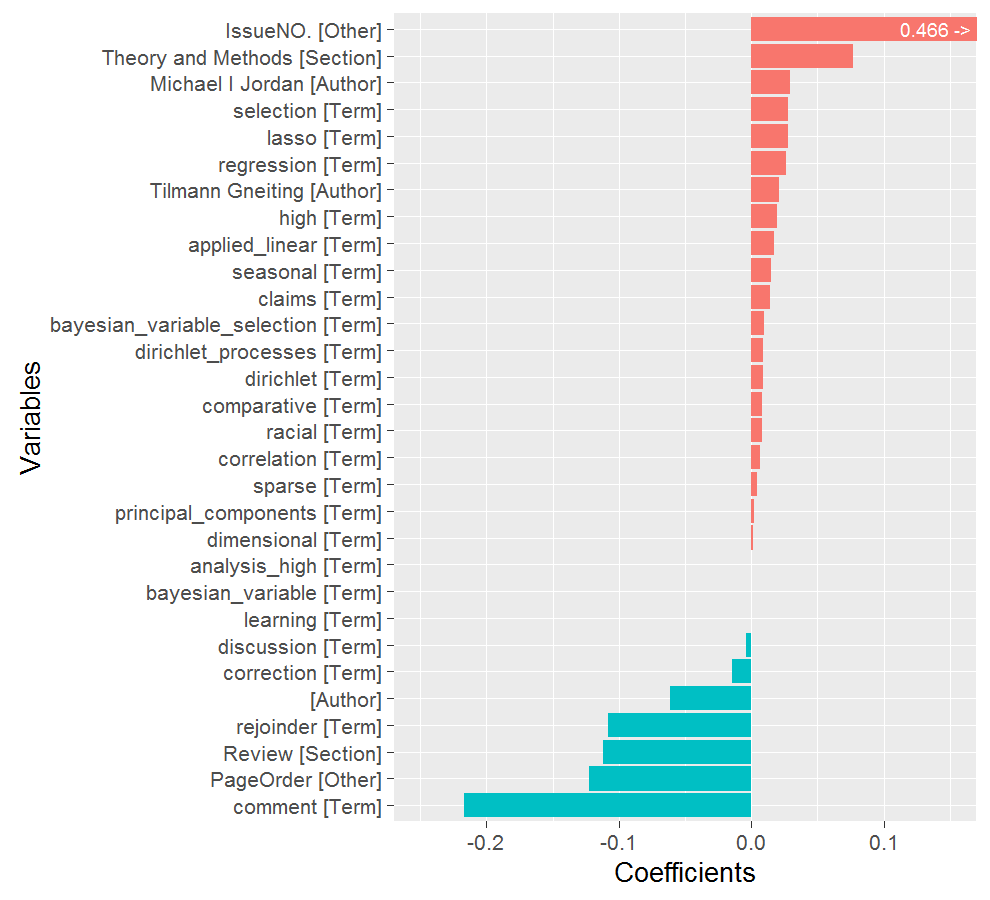
在 Lasso 回归中,我们选取罚参数使得有30个非零变量被选出,然后将它们按照系数大小做成下面这张图。 注意到图中没有包括截距项,而且其中一个变量,文章所在的期数(IssueNO.), 因为系数太大影响图片美观,所以对它的柱形进行了截断,其真实的数值标注在柱形上。
结果分析
下面就这结果简单解释一下,大体上是我自己的理解,所以不一定靠谱,各位看官就当游戏好了。
用 Lasso 筛选出的变量可以分成下面这几类:
- 文章的期刊属性:IssueNO. 系数为正且非常大,说明读者更喜欢阅读最新的文章;PageOrder 系数为负,说明越靠后的文章,阅读量通常越小。(竞价排名现象有木有!)
- 文章所属的类别:正系数排第二的是文章类别 Theory and Methods。JASA 的文章主要有两个类别,应用类(Applications and Case Studies)和方法类(Theory and Methods),由此可以看出 JASA 的读者更关心统计模型和方法,这和 JASA 的风格是比较吻合的。但需要注意的是,这两个类别是2009年之后才有的,之前统一标记为“原创文章”,不加区分,所以这个结果会有一些误差存在。除此之外,评论类(通常是书籍评论)的文章具有负的系数,说明读者对于这一部分的文章通常不关心。
- 文章作者:结果中特别标注出了两位统计学家:Michael Jordan 和 Tilmann Gneiting。Jordan 是公认的统计机器学习大牛,Gneiting 是概率和预测理论的专家,这些说明了他们的领军效应。图中还有一项空白的作者,系数为负,这通常是评论类的文章,在网页上没有标明作者,所以其结果与上一点中的评论类是类似的。
- 文章标题:这算是本文的正题了。先来看看“黑名单”:阅读量较小的文章通常是讨论(discussion),修正(correction),评论(comment)和反驳(rejoinder),它们是其他文章的附属品,所以关注度自然也小。而“红名单”中的词项基本上反映了过去十年统计学研究的流行趋势,例如高维问题(high dimensional, principal components),变量选择(regression, selection, lasso, sparse, Bayesian variable selection),非独立型数据(correlation),Dirichlet 过程(Dirichlet processes)等。由于这些词语的曝光率很高,所以相应地,以这些词作为标题的文章也倾向于有更高的下载量。还有一个相对特殊的 racial 因为涉及敏感的种族问题,所以也比较吸引眼球。
最后的话
不论上述解释是否靠谱,通过本文的统计分析,我们还是发现了一些有趣的结果。当然,在有些方面本文做了不少简化,所以结果也还有提升的空间。下面我简单列举了一些,供感兴趣的读者进一步分析之用:
- 构建词项字典的时候,没有考虑词性变化,比如单复数和时态等。在文本分析中,合并相同词根的过程通常叫 Stemming,在 R 中
SnowballC等软件包提供了相应的函数,但并不十分完美。 - 网站的下载量统计是从2011年6月25日开始的,这意味着早期的文章有一些下载量没有统计到,所以会造成一些偏差。期数(IssueNO.)具有非常大的系数也与此有关。
- 从数据来源上说,还可以考虑加上文章的摘要,因为它提供了更多的文本信息。但另一方面,摘要的眼球效应就不如标题,所以用摘要中的词频来解释文章的阅读量,效果会打一些折扣。
- 本文的建模用的是线性模型(Lasso)。要衡量变量的重要性,还可以考虑使用一些非线性的模型,如随机森林中的变量重要性指标等。
最后的最后,我们通过论文标题这个小窗口瞥见了统计学过去十年的一个缩影。下一个十年又会是怎样的光景呢?我们拭目以待。
附:文中数据和代码都放在 GitHub 上。
关于作者
邱怡轩普渡大学统计系博士,现为卡耐基梅隆大学博士后,感兴趣的方向包括计算统计学、机器学习、大型数据处理等,参与翻译了《应用预测建模》《R语言编程艺术》《ggplot2:数据分析与图形艺术》等经典书籍,是 showtext、RSpectra、recosystem、prettydoc 等流行R软件包的作者。 |  |
敬告各位友媒,如需转载,请与统计之都小编联系(直接留言或发至邮箱:editor@cos.name),获准转载的请在显著位置注明作者和出处(转载自:统计之都),并在文章结尾处附上统计之都微信二维码。

发表/查看评论